Blog post written by Andrea Grütter (28 October 2020)
Another week, another blog post, another issue we have when transcribing! Today we are going to tell you about another challenge we’ve been facing, namely the transcription of the letter “R”.
“R” is similar to letters such as “N” and “B” in that they have different shapes when in uppercase and lowercase. You would think that that means that transcribing them as uppercase or lowercase would be easy, but no! Since the petitioners from our corpus did not receive formal education and therefore did not formally learn how to write (you can read more about this and other transcription challenges in our previous blog posts here, here and here), it is possible that they did not make the distinction in the same way we do now. Writing the same shape but in a slightly larger or smaller version may have been sufficient for them to distinguish between uppercase vs. lowercase. In particular, the writing of the character which would traditionally be viewed as lowercase, i.e. <r>, is sometimes written as larger than the other letters.
Additionally, when a letter is in word-initial position, it is sometimes written differently than it is in the middle of a word. It is therefore possible that the letter is written differently due to its word-initial position, rather than it necessarily being uppercase. To make things even more complicated, word-initial letters when the word is the beginning of a line are sometimes also written differently. However, we will not be looking at line-initial and word-initial letters in this blogpost.
To illustrate the challenge, let’s look at examples from letters written by the same person in 1833 and 1834.
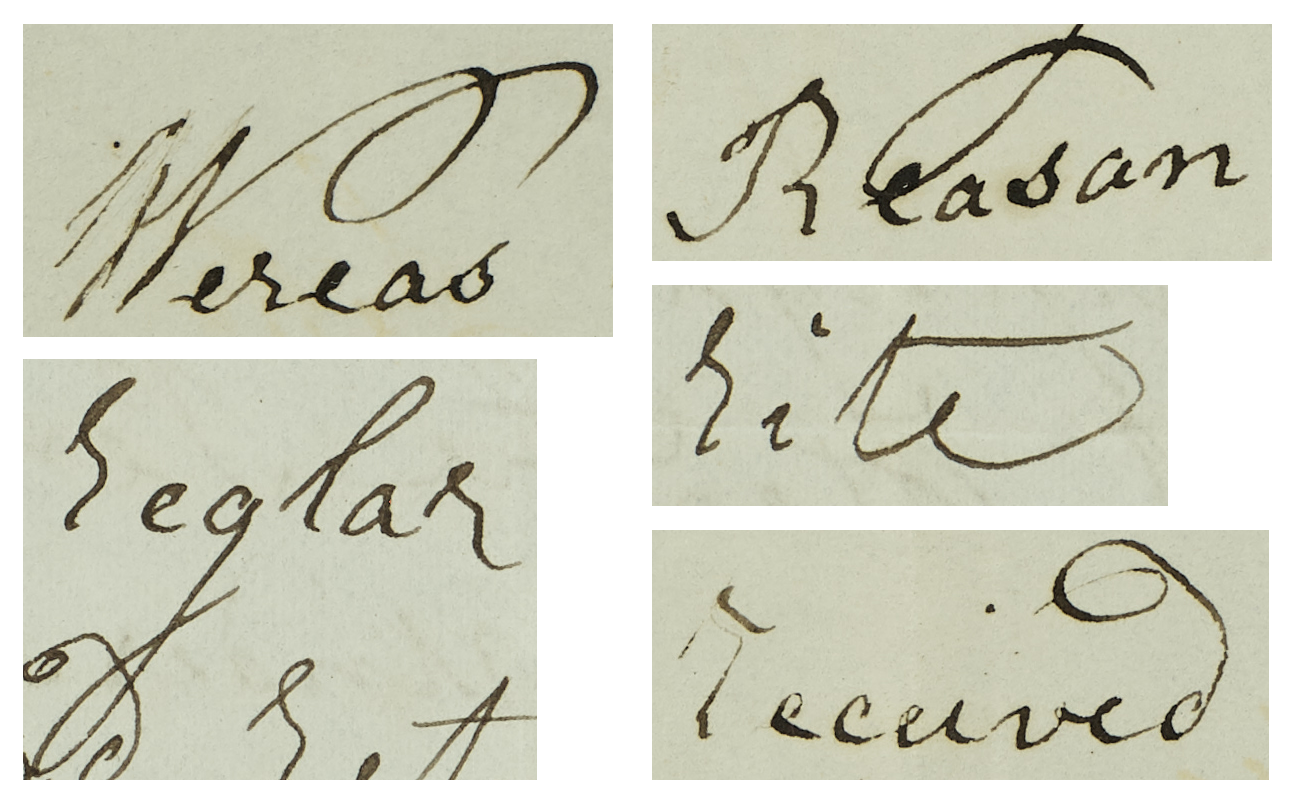
In their handwriting, when “R” appears in the middle of a word, such as ‘Wereas’, it is clearly a lowercase. However, the word-initial “R” is larger than the other letters in the word, which is illustrated in the examples ‘received’, ‘rite’ and ‘reglar’. It could be safe to assume that these are actually uppercase “R”s, but there is one case where it is clearly an uppercase letter: ‘Reasan’. This example suggests that the person writing this letter is aware of the different graphs for uppercase and lowercase “R”s. It could therefore be assumed that the word-initial “R” is lowercase, yet they are clearly larger than the other letters. According to our twitter poll on October 23rd 2020, it seems that people lean towards reading it as lowercase, but a good proportion of people nevertheless would transcribe it as uppercase. You can find the tweet here.
A factor that contributes to this being a challenge for this project is that we are making machine-readable transcriptions of these letters, and our transcription options are binary (<r> and <R>), unless we would want to introduce an additional symbol which would represent an “R” that is written in lowercase but is larger than the other letters. But is the introduction of this symbol and its encoding worth it? If not, how do we decide whether they are uppercase or lowercase? Will all the cases of “R”s that appear to be larger be labeled in the same way, or will some be categorized as uppercase and others as lowercase? If the latter is the case, where do we draw the line? These are some questions for you to think about, and for us to decide on!