Tables des matières
-
- Introduction
- Méthodologie
- Résultats
- Analyse
- Conclusion
Le corpus fourni est celui des archives de la Gazette de Lausanne et du Journal de Genève entre 1798 et 1998.
Nous avons décidé de réduire cette période dans notre étude pour plusieurs raisons : les performances du logiciel OCR (reconnaissance optique de caractères) sur les archives précédant 1900 étant très pauvres, nous avons exclu les articles antérieurs à cette date.
Nous considérons donc uniquement le XXe siècle, puisque, comme nous l’avons précisé dans la contextualisation, c’est à partir de cette période que le sujet des violences faites aux femmes est entré dans la sphère publique.
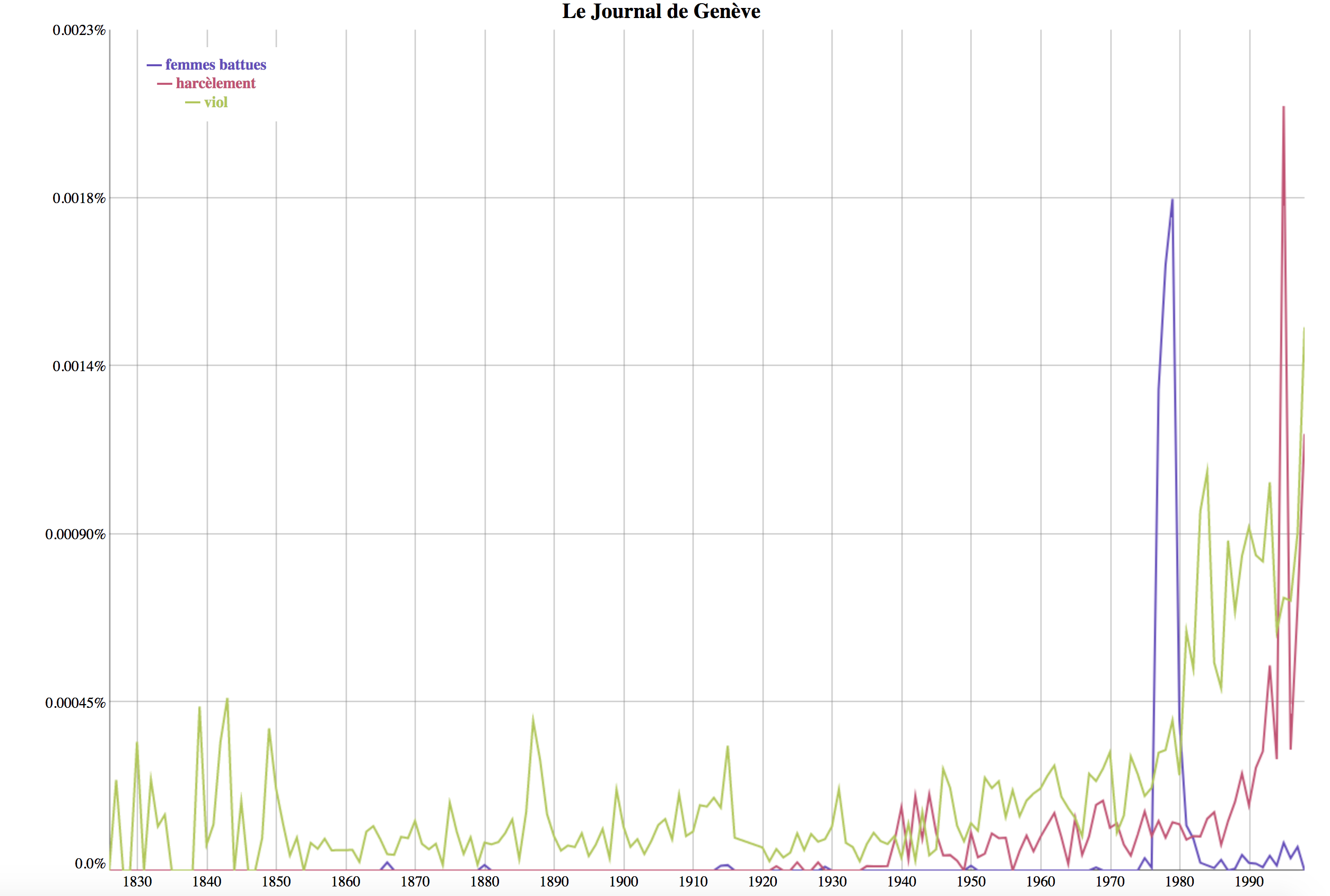
Nous avons dans un premier temps utilisé l’outil n-gram viewer du DHLab afin d’estimer la fréquence temporelle de certains termes. Un exemple de recherche dans le Journal de Genève avec les mots-clés « femmes battues », « harcèlement » et « viol » est présenté dans la figure 1.
À la suite de cette première approche, nous avons dressé une liste de mots-clés essentiels relatifs aux différentes formes de violence pour extraire notre propre sous-corpus à partir de celui des archives de la Gazette de Lausanne et du Journal de Genève. Nous avons pour cela développé un script python permettant d’obtenir tous les articles de la période précédemment choisie (1900-1998) contenant des mots de cette liste.
Dans ce script, nous avons séparé nos mots-clés en deux expressions régulières, afin de les combiner pour s’assurer la présence d’au moins un mot de chacune dans les articles retenus.
La première contient les mots « harcèlement », « viol », « violence », « battue », « maltraitance/tée » ainsi que toutes leurs variantes syntaxiques et la deuxième contient les mots « femme » et « conjugal » (aussi sous toutes leurs formes). De cette manière, nous sommes confiants dans le fait d’avoir retenu une majorité d’articles ayant spécifiquement rapport aux violences contre les femmes.
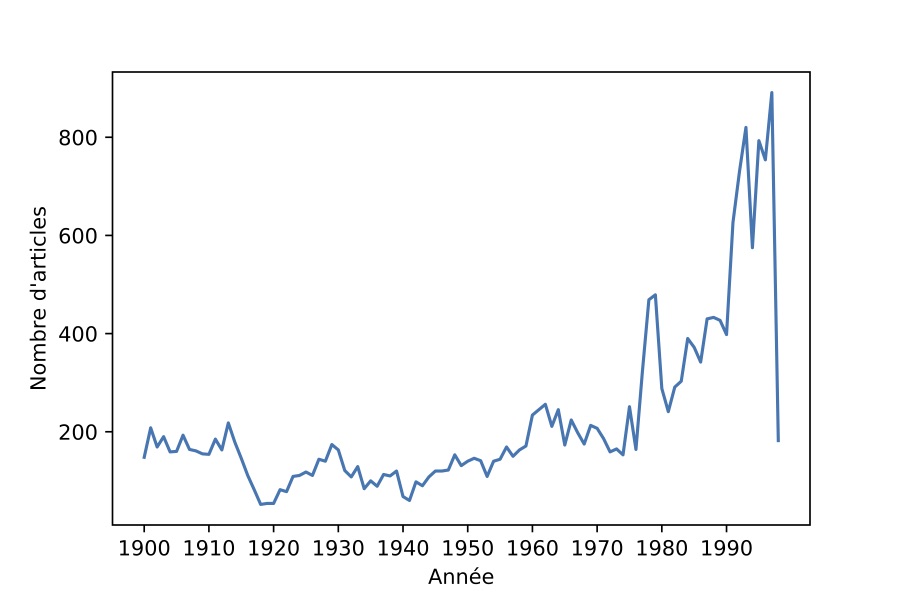
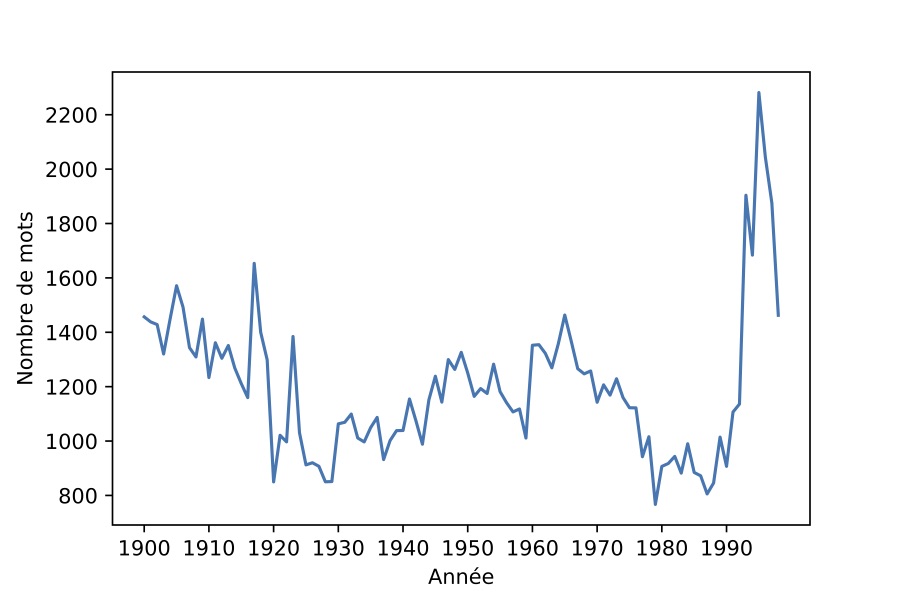
Nous avons obtenu ainsi un corpus de 21’869 articles, dont nous avons tracé la distribution par année dans la figure 2, ainsi que leur longueur moyenne par année dans la figure 3. Les deux graphes présentent des variations similaires avec une forte croissance à partir des années 1990.
En utilisant le logiciel IRaMuTeQ, nous avons d’abord étudié la répartition des mots dans le corpus, ainsi que leurs fréquences.
Enfin, leur classification en champs lexicaux par la méthode de Reinert nous a permis d’identifier les différents cadres dans lesquels le thème de la violence contre les femmes est abordé.
Les résultats de ces différentes analyses des données textuelles de notre corpus sont décrits dans la partie suivante.