
L’URSS de Brejnev vue par les médias suisses
Recherche par mots-clé par Python

Dans les détails, un script python s’occupe de parcourir les archives xml à la recherche des mots-clés. Ceux-ci doivent être cités de manière identique dans le texte et le dictionnaire, au caractère près. Une expression contenant plusieurs mots doit ainsi apparaitre dans le même ordre avec tous les mots identiques. Les majuscules ont aussi leur importance et ne sont pas équivalentes aux minuscules. C’est pourquoi la construction des dictionnaires relève d’une grande importance et doit constamment être améliorée grâce à de nouvelles analyses.
Analyse par Iramuteq et Gephi

Le résultat de la recherche par mots-clé par Python est mis en forme dans un unique fichier texte lisible par le logiciel Iramuteq (« Logiciel Iramuteq », [11]) qui effectue des analyses sémantiques du corpus. Les principaux apports de ce programme viennent de l’analyse de similitudes et la classification par méthode Reinert ou hiérarchique descendante(CHD). La première permet de rendre compte des liens entre les mots, la dernière regroupe les occurrences de tous les mots en classes, rendant l’étude des textes plus facile.
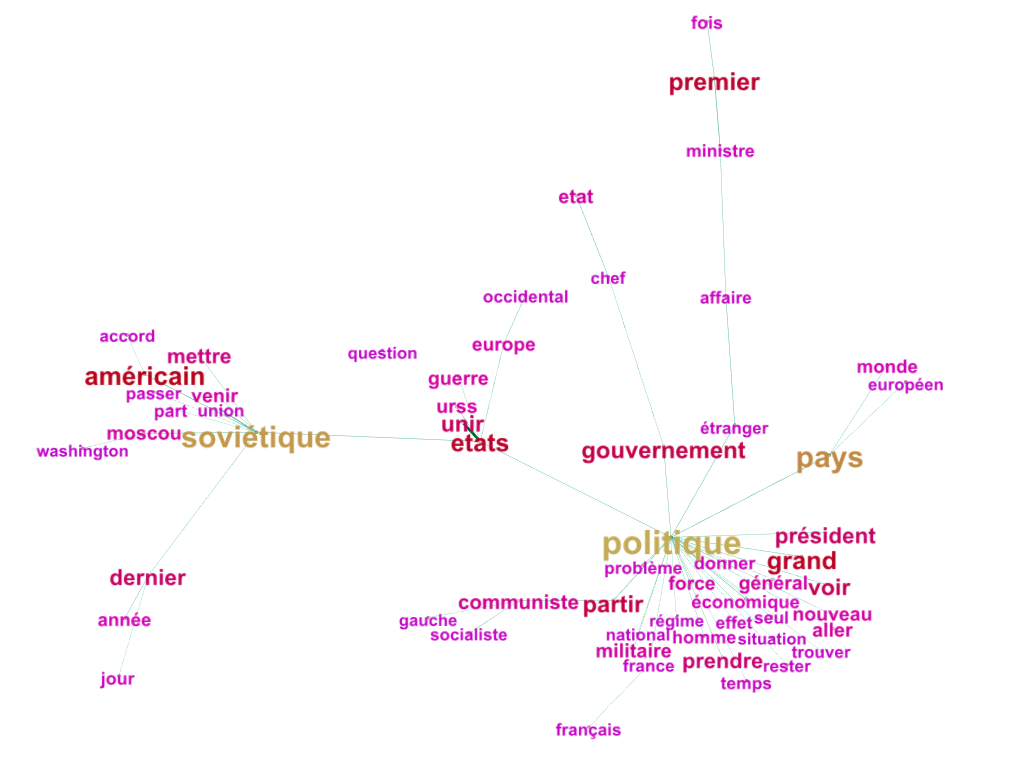
L’analyse de similitudes deviendra plus précise avec l’affinement des dictionnaires. Graphiquement, le logiciel Gephi (« Logiciel Gephi », [10]) est utilisé pour améliorer leur présentation. De cette manière, les graphiques deviennent plus aérés et un tri des mots les plus pertinents est possible par l’utilisateur.
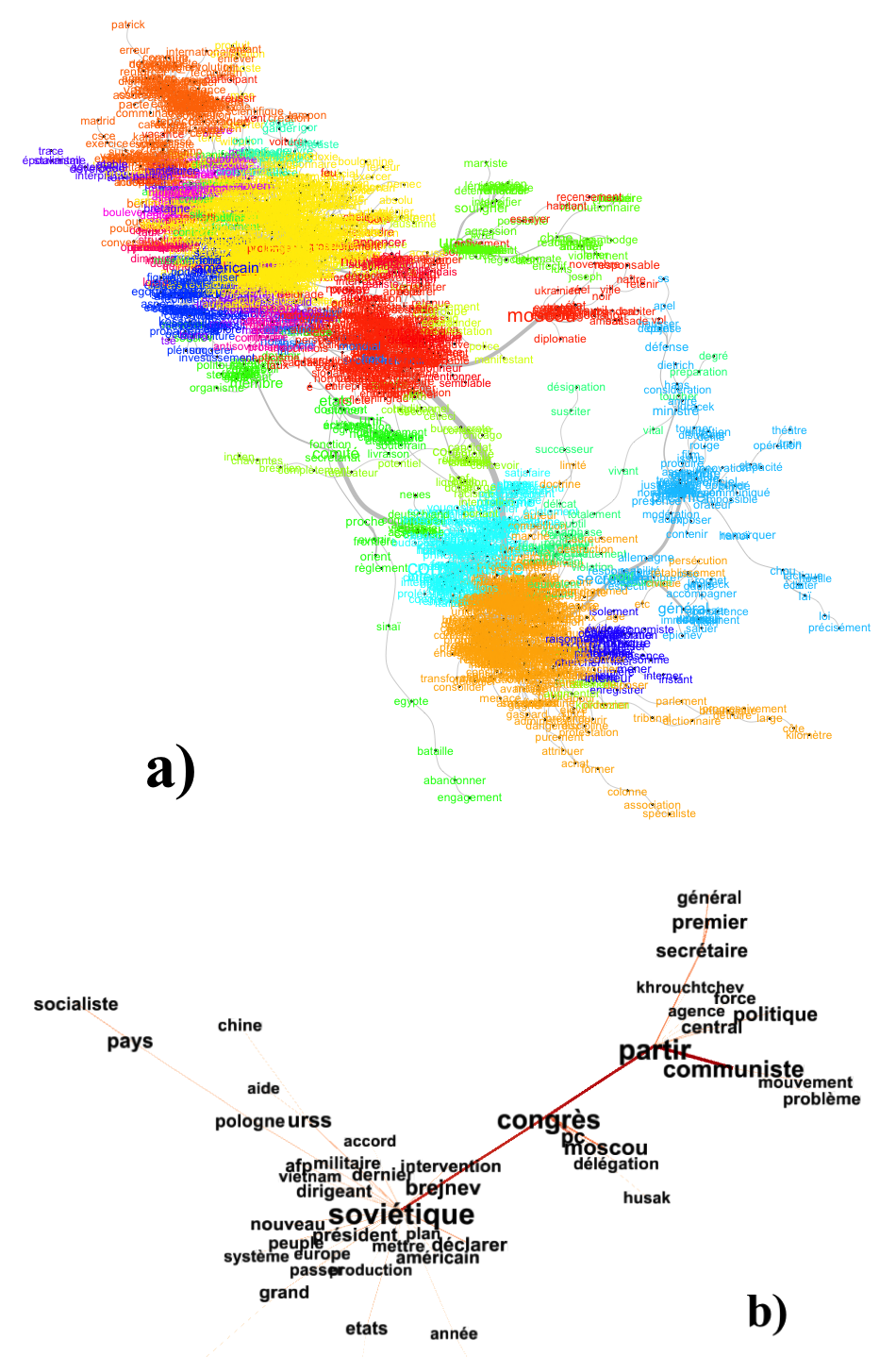
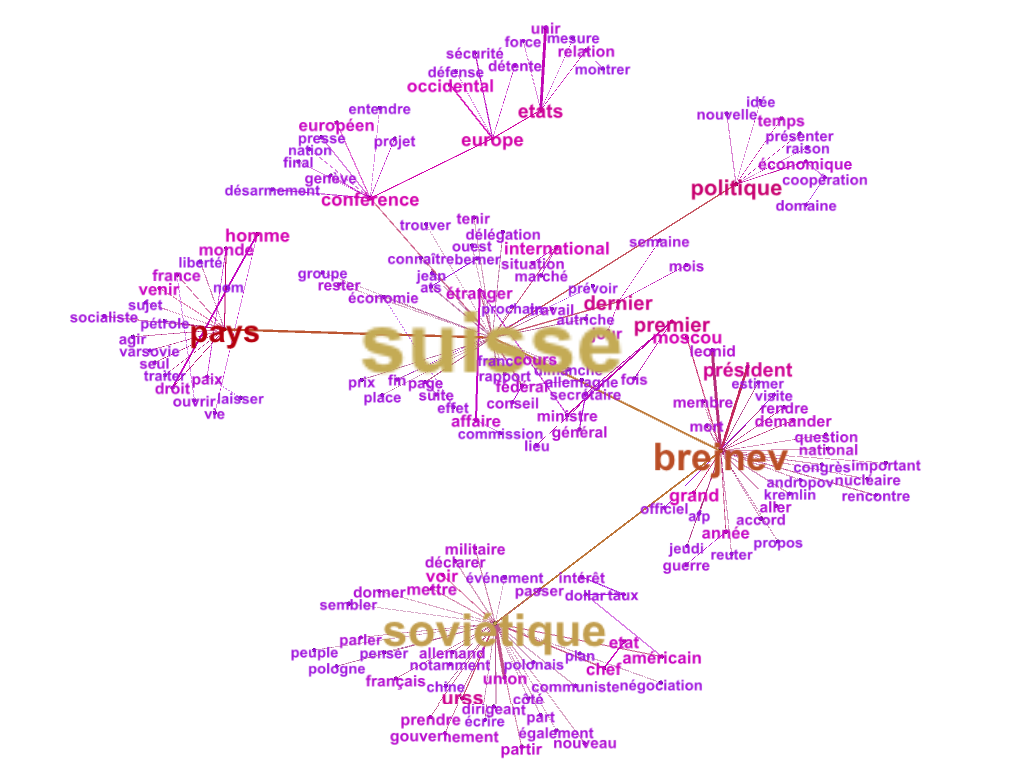
Extraction de mots dans un contexte et historique des occurrences
Pour finir la liste des méthodes d’analyse, un autre script python se concentrera, lui, exclusivement sur les occurrences de certains mots. Grâce à l’utilisation d’un dictionnaire principal, le programme est capable de compter les apparitions de certaines expressions seulement lorsqu’elles sont en présence d’un mot du dictionnaire. Il permet ainsi d’analyser des mots communs très récurrents dans les articles mais uniquement lorsqu’ils sont pertinents face au thème recherché. Un exemple peut être le mot « paix », qui apparait dans une multitude de contextes, mais seul celui de l’Union Soviétique nous intéresse. De cette manière, le mot « paix » qui apparaitrait ailleurs sera ignoré, et le résultat final devient analysable comme sur la figure 8.
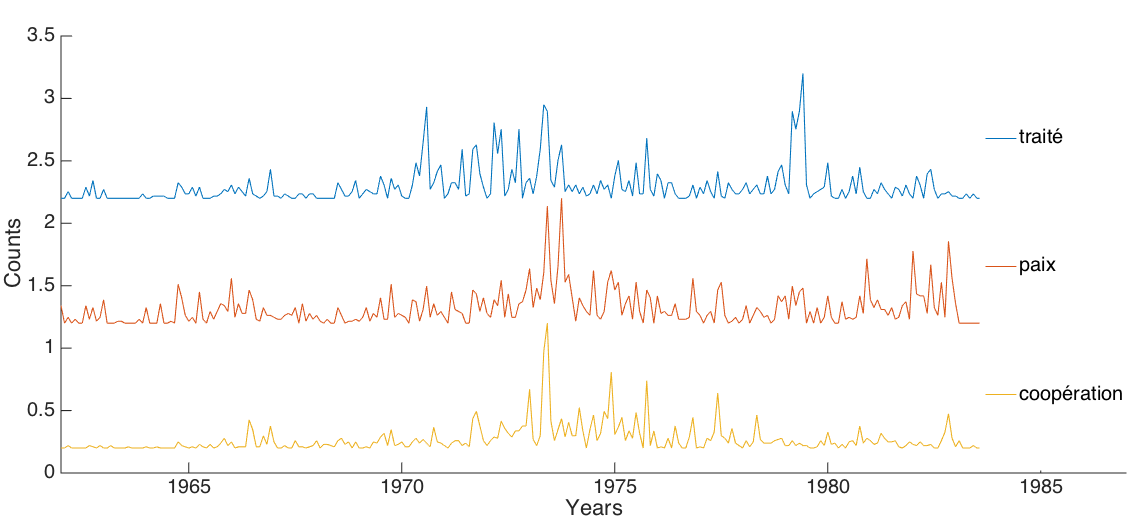
Comme on peut le voir, la période intermédiaire entre Prague(1968) et le début de la guerre d’Afghanistan(1979) est plus riches en mots
Difficultés
-
- Les premières listes de mots-clés furent basées uniquement sur des considérations historiques, il va être capital de pouvoir prouver que tous les événements importants y sont bien représentés. Si nécessaire, quelques adaptations seront effectuées.
-
- Le traitement correct des caractères par le script est capricieux : les majuscules par exemple sont différentes de leurs homologues minuscules. Ceci peut être un avantage comme un inconvénient : le programme peut rater certains mots qui auraient mené à un article très pertinent, mais peut aussi différencier certains noms propres de leurs homologues communs.
-
- La programmation en python doit être rigoureuse afin de ne pas introduire d’erreurs d’analyse postérieure.
Le logiciel Iramuteq a parfois du mal à interpréter certaines déclinaisons de mots. Par exemple « parti » de parti communiste, qui apparaît un grand nombre de fois, sera interprété comme une déclinaison du verbe partir, ce qui n’est pas le cas. Une solution possible, qui fut appliquée a certain corpus, est de filtrer ce type de mots dans les scripts python, de les réécrire avec un tiret bas au lieu de l’espace. - L’interprétation des analyses sémantiques d’Iramuteq est laissée à l’œ humain. Parfois elle est évidente, parfois elle peut être très compliquée. Comme notre démarche se base beaucoup sur les résultats antérieurs pour les affiner ensuite, cette étape sera très importante.
- La programmation en python doit être rigoureuse afin de ne pas introduire d’erreurs d’analyse postérieure.