
L’importance de la Chine dans la presse libérale romande au XXe siècle
- Introduction
- Contexte historique
- Méthodologie digitale
- Interprétation des résultats
- Exemples d’articles indésirables
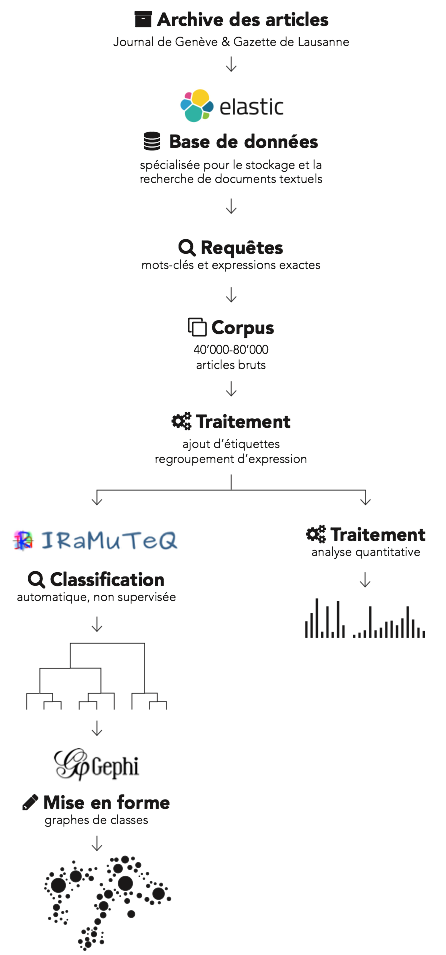
Notre méthodologie peut se résumer ainsi : recherches préliminaires dans les archives pour estimer la taille et la quantité d’information à gérer, travail d’indexation d’un ensemble ciblé d’articles dans une base de données conçue pour ce type de document, recherches détaillées dans les articles pour constituer un corpus dédié à la Chine, étiquetage des articles, analyse quantitative et enfin, réalisation de visualisations par rapport aux thèmes traités.
Corpus
La constitution du corpus est la première étape. Après une brève analyse de l’ensemble des données avec de simples scripts, cette méthode nous a paru impraticable pour obtenir des résultats rapides et affiner de façon incrémentale notre base de documents. Nous avons opéré avec une recherche par mots-clés – dont la liste est similaire à celle présentée plus loin – sur l’ensemble des articles. Nous en avons obtenu environ 100’000.
Pour évaluer la qualité de nos premiers résultats, nous avons appliqué la stratégie suivante : à plusieurs reprises, nous avons choisi cinquante articles au hasard et nous avons relevé les articles indésirables pour identifier leurs caractéristiques. En annexe figurent des classes typiques trouvées avec cette méthode.
Base de données
Cette première analyse nous a donné une vue d’ensemble des articles portant sur notre sujet, mais ne nous a pas permis de les collecter. Afin de faciliter la recherche, nous avons choisi un moteur d’indexation de documents, c’est-à-dire un logiciel voué à recevoir des documents en état brut et à les transformer (indexer) dans une représentation pratique et rapide pour la recherche. Ces transformations peuvent être par exemple la lemmatisation – c’est-à-dire le fait de ne garder que les racines des mots, de découper les mots en n-grammes (groupes de mots) ou de garder une représentation phonétique des mots – et la création d’annuaires inversés – une structure qui permet, pour un mot donné de retrouver les articles correspondants.
Concrètement, nous avons choisi Elasticsearch pour ce rôle et avons inséré la totalité des articles des archives. Les transformations appliquées aux documents sont les suivantes : premièrement suppression des élisions (par exemple « l’arbre » considéré comme « le arbre » par le moteur d’indexation), suppression des caractères spéciaux qui ne sont généralement pas utilisés à la rédaction pour enlever les artefacts de la reconnaissance optique et, enfin, lemmatisation des entrées.
Cette indexation effectuée, nous avons pu profiter de la puissance du logiciel pour faire des recherches aussi bien par mots-clés, booléennes (inclure ceci ET pas cela, inclure ceci OU cela) ou par phrase exacte (« Révolution culturelle »). Nous avons demandé les documents qui figuraient parmi l’une des conditions suivantes sur le titre et le contenu (la casse ne compte pas) :
- Mots-clés : Chine, chinois, chinoise, pékin, bejing, nankin, changai, shangai, tian’anmen, tiananmen, guangdong, sichuan, chengdu, wuhan, xiaping, mao, sino, shaoqi
- Expressions exactes : « Révolution Culturelle », « sino-japonais », « Empire du milieu », « bande des quatre », « sino-helvétique »
Cette requête a permis d’obtenir plus de 150’000 articles. Nos premières recherches à l’aide de scripts avaient mis en évidence des articles indésirables : horaires de magasins, événements culturels en Suisse sans rapport avec la Chine, horaires de spectacles ou encore dépêches internationales dont le contenu porte sur beaucoup de sujets, mais dont seule une phrase est réservée à la Chine. Ces articles étaient compris dans les résultats de cette requête. Pour les omettre, nous avons mis en place deux stratégies.
La première consiste à utiliser le score attribué à un document par Elasticsearch lors d’une requête. Cet indice est calculé à partir de trois paramètres : la fréquence du terme (le nombre d’apparitions d’un terme recherché dans un document), la fréquence inverse (le nombre d’apparitions du terme dans la totalité des documents) et enfin, le nombre de mots total pour une apparition. Par exemple, un terme recherché apparaissant dans un titre de dix mots aura un impact plus important qu’un terme trouvé dans un article de plusieurs centaines de mots – il s’agit ici de la probabilité que l’article trouvé parle du sujet qui nous intéresse. La seconde est basée sur le filtrage des mauvais articles. Nous avons interrogé Elasticsearch avec une requête portant sur les articles que nous voulions enlever : « dépêche», « Dépêches internationales » (près de 5’000 résultats).
Étiquetage des articles
Une fois les articles sélectionnés, nous mettons en place un étiquetage automatique des articles pour la suite du travail :
- Présence en Une ou sur la dernière page du journal
- Présence de la Suisse dans l’article
- Publication (Gazette de Lausanne ou Journal de Genève)
- Année de publication
Suite à nos premières expériences avec Iramuteq, nous avons aussi modifié certains articles, par exemple pour représenter « Parti » sous forme de « Parti_Communiste » afin qu’il ne soit pas confondu avec la racine « Partir ». Nous avons procédé de manière identique pour « New York », « États Unis » et « Chine populaire ».
Analyse de texte
La dernière partie de notre travail méthodologique réside dans l’analyse des textes. Il s’agit ici de déterminer les thématiques abordées dans la totalité des articles de notre corpus non pas en prenant un article comme unité, mais des segments de textes. Ainsi un article peut appartenir à plusieurs thèmes. Nous avons choisi d’utiliser le logiciel Iramuteq car il contenait l’ensemble des outils pour analyser le français. Sur la base d’analyses statistiques, le logiciel classe les segments de textes de chaque article en un nombre variable de profils. Le nombre de classes et leur contenu sont entièrement déterminés par la méthode de Reinert. Il s’agit d’une approche non supervisée car elle n’apprend pas en suivant un exemple donné par un humain. Ensuite, il est possible d’utiliser les étiquettes définies pour appliquer ce type d’analyse à un ensemble d’articles plus restreints ou pour projeter une classe d’articles dans le temps (à travers les années) ou dans le journal (grâce aux marqueurs de pages). Nous effectuons les analyses suivantes : classification du corpus entier, des articles en Une et des articles de dernières pages.
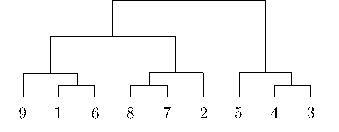
Six classes parmi neuf sont retenues pour l’analyse : 2 à 5, 8 et 9. Malgré d’intenses recherches, dont l’analyse des antiprofils, classification comme sous corpus, parcours manuels des segments de textes, nous ne sommes pas parvenus à extraire des informations utiles des classes restantes. Ces classes contenaient beaucoup de segments indésirables et de contenu hors sujets.
Visualisations
Les visualisations ont été réalisées à partir de la classification produite par Iramuteq. Chaque classe retenue est représentée par un graphe mettant en évidence l’importance de la relation entre les mots composant les segments de texte. Ainsi, deux mots appartenant à une classe figurant souvent côte à côte auront un lien très important sur le graphe. L’intérêt de cette visualisation est non seulement de présenter les thématiques, les personnages ou les lieux, mais aussi de représenter des communautés[1] de mots. Les graphes de classes sont issus de données brutes mises en forme à l’aide du logiciel Gephi. Chaque graphe a reçu un traitement spécifique pour mettre en valeur les thématiques : nous avons coloré les nœuds en nous basant sur une analyse de communauté, ajusté la taille des nœuds en fonction de leur importance (soit en terme de nombre de liens entrant et sortant ou en nous basant sur les données brutes fournies par Iramuteq) et nous avons agrégé les mots similaires qui avaient échappé à notre filtrage initial. Par exemple, les multiples graphies des lieux et des personnages. Ce regroupement s’est avéré efficace puisqu’il nous a permis de choisir comment agréger l’importance d’un nœud dans le graphe. Des nœuds de petite taille figurent intentionnellement autour des sujets importants pour mettre en évidence le vocabulaire rattaché. Enfin, nous avons décidé de contextualiser nos différents graphes en les mettant en perspective avec un histogramme représentant la période de temps où ces classes ont été considérées comme pertinente par l’algorithme. Ces histogrammes sont basés sur les valeurs obtenues à partir d’un test statistique sur chaque segment de texte. Ces données sont issues d’Iramuteq. Nous utilisons les étiquettes représentant les années pour ce test. Les classes seront décrites en détail dans la partie suivante.
[1] clustering en anglais