Table des matières
Périodes et mots-clés
Pour constituer un corpus exploitable pour notre étude, nous avons dû limiter nos sources temporellement et exclure les articles qui étaient hors sujet. Nous avons gardé l’ensemble de la période de chaque dictature pour leur étude comparative et avons donc importé les articles de 1933-1976 pour le Portugal, 1936-1976 pour l’Espagne et 1967-1976 pour la Grèce des deux journaux avant d’en faire le tri en plusieurs étapes.
Durant la première étape, nous avons constitué un ensemble de mots-clés afin d’extraire les articles pertinents en éliminant au maximum ceux qui ne concernaient pas la politique de ces régimes.
Pour le Portugal, la recherche d’articles contenant les mots-clés « Salazar » et « Caetano » s’avère assez efficace : par échantillonnage, nous constatons qu’une grande majorité des articles retenus traite bien de notre sujet.
Au contraire, en ce qui concerne l’Espagne, le nom du général Franco est peu pertinent car c’est un nom courant et qui est présent dans de nombreux articles qui évoquent la France (relations franco-allemandes, par exemple). Cependant, extraire les articles qui contiennent à la fois les mots « Espagne » et « Franco » (avec majuscule et sans ponctuations après) améliore considérablement la qualité des résultats, qui est alors désormais comparable à celle du Portugal.
Pour la Grèce, nous pensions que l’orthographe des noms des colonels pouvait varier d’un article à l’autre. Pour Papadopoulos, l’orthographe est standard. Cependant, le nom de « Pattakos » peut effectivement être orthographié « Patakos » et « Makarezos » est également orthographié « Makaresos ». Nous avons donc utilisé toutes ces variantes de noms pour constituer notre corpus.
Traitement et étapes de la recherche
Afin de prévenir les éventuels problèmes liés à ces différentes graphies, nous avons dans un premier temps harmonisé l’orthographe en éditant les textes concernés. Deuxièmement, nous avons exécuté des scripts afin de récupérer les articles qui concernaient les régimes étudiés (à l’aide des mots-clés décrits ci-dessus). Ensuite, en échantillonnant le corpus, nous avons constaté qu’une importante partie des articles concernaient le sport. Nous avions pensé à repérer les numéros des pages sportives et à les supprimer mais nous nous sommes rendus compte que leur position dans le journal variait et que cette approche était donc inexploitable. Nous avons ainsi affiné la recherche en supprimant tous les articles qui contenaient les mots : sport, match, foot et football. Après cette étape, les corpus sont constitués d’environ 600, 1600, 6500 articles pour la Grèce, le Portugal et l ‘Espagne, respectivement.
Finalement, nous avons enlevé les balises XML, récupéré les métadonnées utiles (date, titre, page) et utilisé un script de mise en forme pour rendre les articles compatibles avec Iramuteq.
Nous obtenons ainsi six corpus : un par pays et par journal. Cette distinction entre le Journal de Genève et la Gazette de Lausanne est pertinente pour pouvoir comparer les approches des deux journaux.
Iramuteq et visualisations des premiers résultats
Pour nos analyses, nous avons utilisé Iramuteq, un logiciel libre permettant l’analyse statistique de textes. Parmi les approches disponibles, nous avons privilégié la méthode Reinert qui permet de constituer des classes de mots. Cela nous permet d’isoler les segments de textes qui concernent la politique d’un pays. Par exemple, la classe 2 obtenue avec le corpus Grèce-GDL est représentée par des mots comme résistance, attentat, gauche (voir graphique 1).
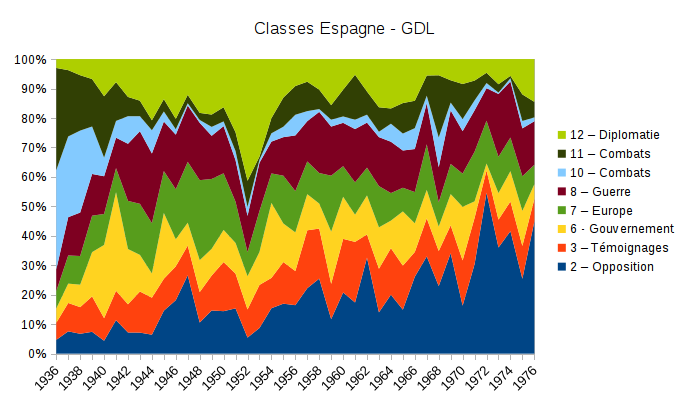
Iramuteq nous offre également la possibilité d’analyser la fréquence relative de ces classes, ce qui est utile pour la comparaison de corpus de tailles différentes. Ces fréquences nous ont également permis de comprendre de quelles manières les régimes et les dirigeants étaient caractérisés par les journaux. Nous avons aussi utilisé les métadonnées récupérées lors de la phase du traitement du corpus, afin de comprendre l’évolution du champ lexical utilisé au fil du temps. Nous avons extrait les données brutes produites par Iramuteq lors de ce traitement afin de visualiser ces changements sous forme de graphiques (voir graphique 2 en exemple).
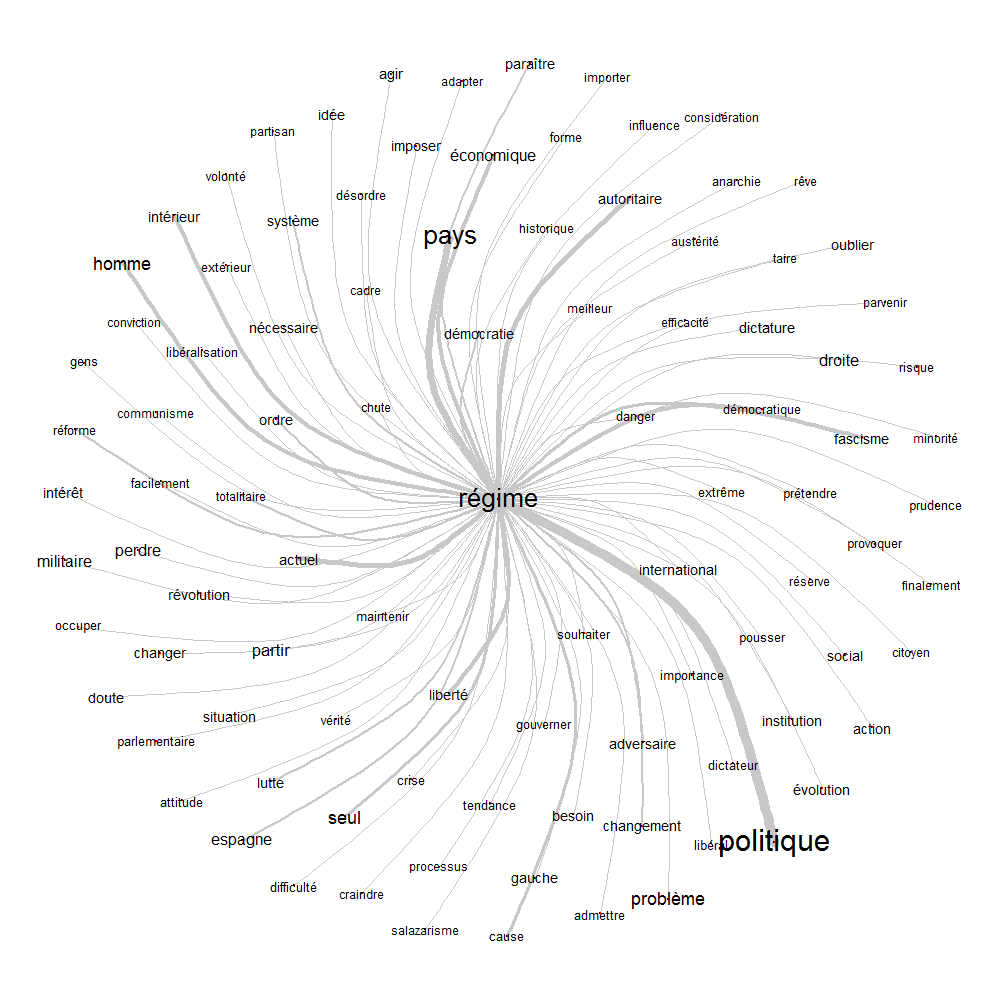
Finalement, nous avons procédé à des analyses de similitudes qui permettent de mettre en évidence les mots souvent associés dans les articles et peuvent être portées sur un graphique, comme c’est le cas pour le mot « régime » donné en exemple (voir graphique 3).