
Données
Les sources mises à notre disposition, les archives numérisées de la Gazette de Lausanne et du Journal de Genève jusqu’en 1998, constituent notre fenêtre sur le débat public engendré par ces divers évènements. En plus de contenir des articles parlant précisément des initiatives en cours, ces archives sont un reflet de la société romande tout au long de la période qui nous intéresse. On y constate par exemple (cf. graphique ci-dessous) que les maximas du nombre d’occurrences du terme immigration, et donc le nombre d’articles en parlant, semblent correspondre à des périodes de réelle augmentation de l’immigration.
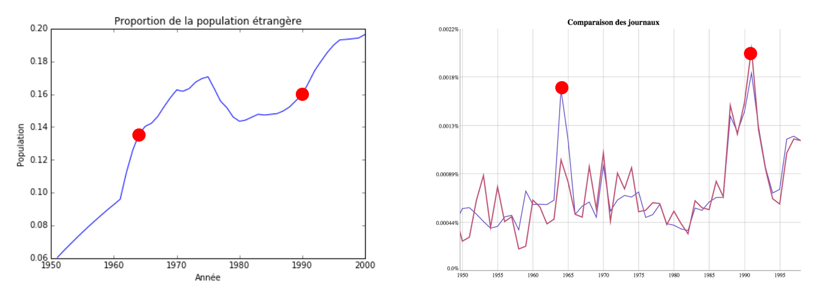
En outre, ces données exhibent une caractéristique qui nous intéresse particulièrement, celle de l’évolution de leur vocabulaire. Elles ne présentent donc pas seulement une image factuelle de leur époque, mais aussi lexicale. Notre travail s’appuiera sur cette particularité de nos sources.
Méthodologie
Le but de notre travail étant d’analyser la dérive linguistique des articles liés à l’immigration en Suisse, nous essayerons de reproduire la méthode développée par Vincent Buntinx au DHLab de l’EPFL, mais uniquement sur un sous-ensemble d’articles et non pas sur toutes les archives.
Il s’agit donc dans un premier temps d’identifier le sous-ensemble d’articles traitant de notre thème. La difficulté de cette étape sera de déterminer exactement les critères de sélection, ou non, d’un article. La recherche par mot-clé, i.e. collectionner tous les articles contenant, par exemple, le mot immigration, sera privilégiée. De tels mots-clés devront être choisis de manière à minimiser leur dépendance à une période précise et devront être assez généraux pour ne pas introduire de biais dans l’ensemble sélectionné. Comme notre approche est plus quantitative que qualitative, la taille du corpus ainsi constitué ne sera pas un obstacle.
Une fois les données choisies, elles seront analysées pour en extraire ce que Buntinx appelle leur noyau lexical, et ce pour chaque année. Il sera ainsi possible de déterminer l’évolution de ce noyau et de découvrir si celle-ci est influencée par le vocabulaire utilisé par les initiatives populaires.
Elaboration de notre corpus
La première étape est de filtrer les articles afin de ne garder que ceux qui traitent de l’immigration en Suisse. Après avoir restreint la période d’intérêt aux année 1950-1998, nous avons cherché à mettre en place un critère de sélection des articles. Ceci a été fait de manière expérimentale, en partant de la tactique naïve consistant à garder tous les articles contenant le mot « immigration », puis en raffinant petit à petit le filtre.
Afin de pouvoir procéder par itérations, chaque nouveau filtre n’était appliqué et évalué que sur un échantillon de 15’000 articles sélectionnés au hasard dans l’entier de l’archive. Cela nous a permis d’éviter le temps de calcul considérable nécessaire au filtrage de la totalité des données.
La procédure finale consiste d’abord à contrôler qu’un article contient le mot « suisse » puis de ne garder un tel article que s’il contient au moins douze instances d’un mot de la liste de mots-clés suivantes :
Apatride, assimilation, naturalisation, sans papier, immigration, étranger, saisonnier, réfugié, asile, xénophobe, intégration, raciste, clandestin, indigène, travailleur étranger (ainsi que leurs variations de singulier/pluriel et de genre).
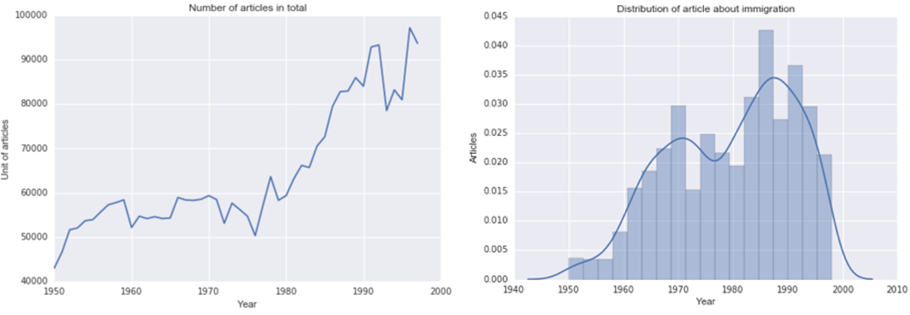
Nous avons finalement obtenu un corpus constitué de 2786 articles. Malgré la présence de certains articles peu cohérents avec notre sujet, la construction du filtre par itération offre une bonne garantie de la légitimité de ce corpus. Si le filtre ne fonctionnait pas, les courbes des deux graphiques ci-dessus se ressembleraient plus.
Méthodologie digitale
Avant d’appliquer la méthode introduite plus haut à notre corpus, nous avons décidé de retirer du texte une liste de mots très communs (articles, prépositions, etc.) afin de réduire la part de bruit dans nos données.
Dans le but de déterminer la manière dont le langage utilisé dans les articles liés à l’immigration évolue d’une année à l’autre, nous avons dû choisir une notion de distance linguistique entre deux ensembles de textes. L’idée sur laquelle nous nous sommes concentrés est celle de noyau lexical et de la distance entre noyaux, qui permet selon Buntinx d’obtenir une bonne représentation de la dérive linguistique.
Le noyau lexical Kx,y d’un corpus de texte entre l’année x et y est l’ensemble des mots apparaissant au moins une fois chaque année entre l’année x et l’année y. De plus, les mots sont ordonnés dans le noyau par leur fréquence dans le texte entier. Une fois le noyau obtenu, la distance entre deux années dans le corpus devient une fonction de la différence de l’ordre des mots d’une année à l’autre. L’évaluation des distances entre années est présentée dans la prochaine section.
Dans un deuxième temps, nous avons décidé de comparer non pas les distances telles que Buntinx les définit mais la taille même des noyaux (nombres de mots), afin de mieux observer les évolutions locales du langage. Nous avons donc essayé de mieux capturer le vocabulaire d’une période en calculant pour chaque année le noyau entre celle-ci et les cinq années suivantes. Nous postulons que les différences de taille entre ces noyaux de cinq ans constituent une bonne représentation de la vitesse des changements linguistiques dans cette région temporelle.