FAIR Data Sharing & Open Research Data Support for FBM UNIL-CHUV Researchers

1. Criteria for Repository Selection
Prioritize Domain-Specific or Data Type-Specific Repositories
Before considering a generalist repository like Zenodo, first check if a data type-specific or domain-specific repository is available. These specialized platforms often provide better visibility and functionality tailored to your field.
For example:
- If you work with large imaging datasets, consider repositories such as BioImage Archive (BIA).
- If your research is in neuroscience, a specialized repository such as E-BRAINS in that domain may offer greater visibility and discoverability than a generalist platform.
Your repository must meet the following criteria:
- Free of Charge, Regardless of Dataset Size → freely accessible repository with no cost for submission or access.
- Tailored Infrastructure for the interested data type → Optimized to host raw and processed data type, with tools for visualizing, downloading, or querying complex datasets.
- Integrated with resources to enhance data accessibility and utility.
- Reliable Long-Term Preservation → the repository Follows robust policies including infrastructure continuity, regular backups, and lifecycle data managementTo support this decision, we provide FAIRshare Explorer, a tool listing recommended repositories by data type and research discipline. Please consult it before choosing where to deposit your data.
- FAIR-Compliant by Design → insures that sample metadata are Findable, Accessible, Interoperable, and Reusable, following community metadata standards and supporting compliance with institutional and funder Open Science mandates (e.g., SNSF, Horizon Europe).
- Flexible Licensing → Ideally supports open licensing options such as Creative Commons CC BY 4.0 or CC0, enabling broad data reuse while ensuring proper attribution.
- European/National Hosting → Ensures compliance with data protection and Open Science standards and policies. https://www.ebi.ac.uk/long-term-data-preservation/
To support this decision, we provide FAIRshare Explorer, a tool listing recommended repositories by data type and research discipline. Please consult it before choosing where to deposit your data.
Mandatory Local Archiving
All data supporting a publication (raw, processed, and analytical) must also be archived on long-term storage provided by DCSR-UNIL or DSI-CHUV (link).
2. Use FAIRShare Explorer ©DSBU Tool to find adapted repository and file formats/metadata Standards

Your Guide to find FAIR, Secure, and Sustainable Data Repositories
What you’ll find in the Explorer:
- Complete list of repositories with key informative details for efficient submission: data types and formats, submission process, metadata standards, sharing licenses, and more
- Repository Usage Recommendations from the FBM Dean’s Office and DSBU
- Indication on the type of support provided by the DSBU
- Filters Tailored for UNIL–CHUV Researcher
- A “Best Fit Repository Finder” to quickly identify:
- Recommended repositories (green)
- Repositories to avoid (red), based on the criteria above
3. Publishing Your Dataset to Data Type-Specific or Discipline-Specific Repositories
Scope: Designed for specific or disciplinary data types, such as:
- Genomic data (ENA: nucleotide sequence data, EGA: human data that requires controlled access).
- RNA sequencing.
- Electron microscopy (EMPIAR: raw image data).
- FACS data (FlowRepository: database of flow cytometry experiments)
- Light microscopy (BioImage Archive: bioimaging data).
- Open research infrastructure that gathers data, tools and computing facilities for brain-related research (EBRAINS)
Use Recommended Standards for File Formats and Metadata Schemas
To ensure interoperability, discoverability, and long-term reuse, always follow the file formats and metadata schemas endorsed by your chosen repository. These community-driven standards are tailored to each data type and archive—and you can discover them quickly with the FAIRShare Explorer @DSBU tool:
- Accepted File Formats → e.g., OME-TIFF, NIfTI, FASTQ, etc.
- Metadata Standards → e.g., REMBI, MIAME, MIAPE, CDISC, etc.
Use FAIRShare Explorer to:
- Identify the exact formats and schemas required by each repository.
- Read the repository descriptions—including data types supported, submission workflows, licensing rules, and access conditions.
- Access step-by-step deposit instructions and examples for every repository.
4. FBM UNIL–CHUV Zenodo Community if no suitable specialized repository exists
If no suitable specialized repository exists, the FBM Dean’s Office strongly recommends depositing your dataset in the following generalist repository:
Depositing in this community allows you to:
- Receive metadata curation and guidance from the Data Stewardship Biomed Unit (DSBU)
- Increase your dataset’s visibility within and beyond FBM
- Ensure traceability of data produced by the faculty
- Link your dataset to your publication, making it easier to cite and access
We recommend submitting your dataset early, ideally during the manuscript review process, so that it can be referenced and properly cited in your article.
Zenodo FBM/CHUV Community Submission Process – Key Information
- You can only submit drafts (unpublished records) to a Zenodo community.
- Both you and the community curators (DSBU) can edit metadata and files during the review phase.
- Your record can be automatically published once approved by the community curators.
Submit your record for review in 3 simple steps:
- Find the community: Search for “FBM UNIL–CHUV” on Zenodo and go to the community page.
- Submit for review: Upload your dataset and request inclusion.
- Manage your submission: Monitor review status and edit if needed.
File Formats and Metadata Recommended Standards for Zenodo
To ensure interoperability, discoverability, and long-term reuse, it is essential to follow the file formats and metadata schemas recommended by the repository itself. These standards are typically developed in collaboration with the scientific community and tailored to the type of data being archived.
Accepted File Formats → Recommended Standards Files format for unstructred data from our service for data sharing or archiving
Recommended Standards Files format
Ranked in descending order of preference
Text:
• PDF/A
– PDF/X
• Plain text (.txt)
• Open Office (.odt)
• XML / HTML (with schema)
• Word XML (.docx)
• RTF
• LaTeX
Images:
• Bitmap
– TIFF (uncompressed)
– PNG
– JPEG2000
– (GIF)
• Vector
– SVG
Tabular data:
• CSV (comma, tab, semi-colon)
• Open Office (.ods)
• XML / HTML (with schema)
• Excel (.xlsx)
• .SQL
Video:
• MPEG-4 (H.264) (~ MP4)
• Motion JPEG 2000
• MPEG-1/2
Audio:
• WAV (preferably Broadcast Wave Format, LPCM)
• AIFF (LPCM)
• OGG Vorbis
• MP3 MPEG Layer III
• AAC MPEG-4
Metadata Standards → DataCite Metadata schema
Useful standard for describing general research datasets when there is no data category or discipline specific standard.
DataCite Metadata schema
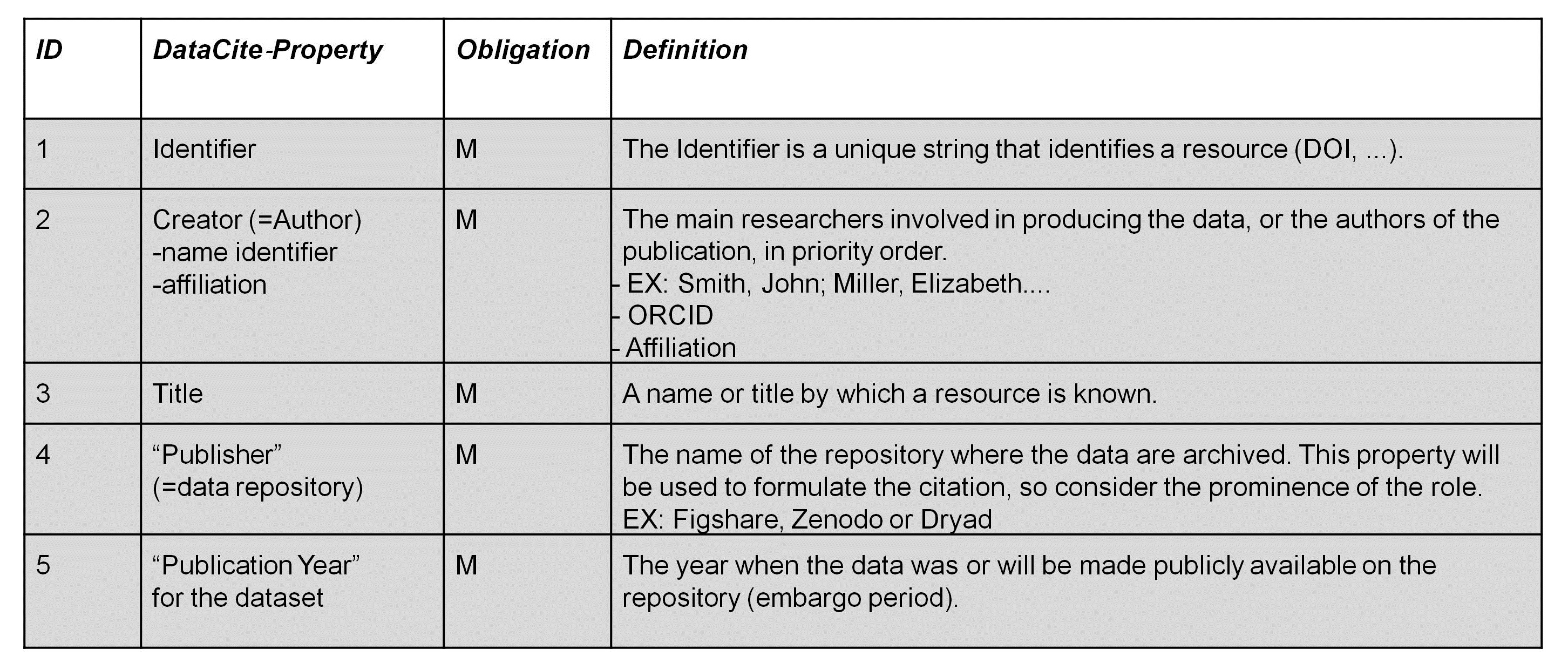
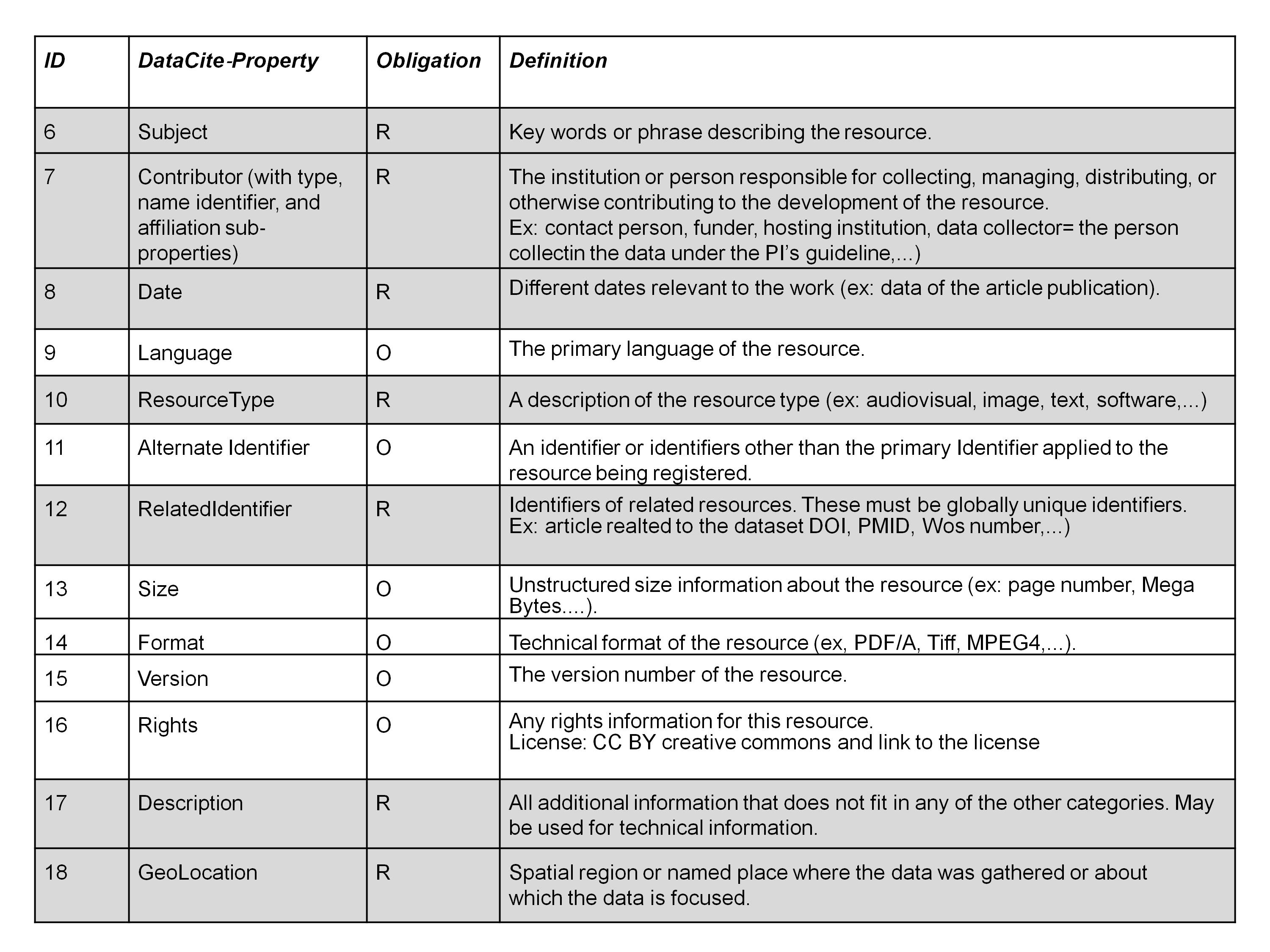
The DataCite Metadata Schema for Publication and Citation of Research Data distinguishes between 3 different levels of obligation for the metadata properties:
- Mandatory (M) properties must be provided,
- Recommended (R) properties are optional, but strongly recommended and
- Optional (O) properties are optional and provide richer description.
Table 1 and table 2 list the different items you should document about your dataset based on the 3 different levels of obligation.
Table 1: DataCite Mandatory Properties
{kind=link}

Table 2: DataCite Recommended and Optional Properties
{kind=link}

5. Use Horus Dataset Catalog for Sensitive Non Anonymized Data at CHUV
Managing sensitive biomedical data requires strict adherence to privacy and confidentiality standards. Open access to such data is contingent upon explicit consent and the anonymization of personal information.
For sensitive datasets that cannot be anonymized, researchers should utilize the HORUS Dataset Catalog at CHUV, developed and managed by the Data Science Group – DSI
Key features of this catalog include:
- Metadata Highlighting: Provides detailed metadata descriptions of sensitive clinical datasets generated at CHUV.
- Controlled Access: Ensures secure access to sensitive datasets in compliance with legal restrictions.
- High visibility and compliance to FAIR international standard: Enables interoperability between the CHUV catalog and external repository Zenodo, automatically transmitting FAIR metadata for public visibility in the FBM UNIL-CHUV Zenodo community.
Submit your Dataset
The DSBU offers end-to-end assistance with depositing sensitive data via the HORUS CHUV catalog:
Process Overview
- Dataset Submission & Metadata Entry: Researchers are supported by the DSBU to upload their dataset into the HORUS Dataset Catalog and fill in all necessary metadata fields describing the dataset.
- Metadata Review & Curation: A data steward (curator) from the DSBU carefully reviews the submission to ensure the metadata is complete, accurate, and compliant with FAIR principles.
- Metadata Publication to Zenodo: Once validated, the metadata is automatically published to the Zenodo FBM UNIL-CHUV Community, making the dataset discoverable on an international level, even though the data itself remains protected on CHUV internal servers.
- Data Access Request by contacting the PI: When other researchers read a publication referring to a dataset hosted in HORUS, or when they browse Zenodo and find the associated metadata, they gain a detailed understanding of the dataset’s content. If they are interested in using the data, they can contact the Principal Investigator (PI) through its e-mail address listed in the metadata.
- Access Evaluation & Agreement: The PI, possibly with a designated review committee, evaluates whether the data access request is legitimate. Criteria include:
- The resquester comply to the Data Sharing Requests and Procedures
- The requester works in a relevant field,
- Their study is clearly aligned with the dataset’s subject and goals,
- A clear scientific justification for the data reuse is provided.
- Collaboration & Data Transfer and Use Agreement (DTUA):
- If the PI and committee approve the request, a collaboration agreement can be established.
- Data can then be shared with the external team under the terms of a CHUV DTUA (The template used for this agreement is based on the one published by SPHN).
- SPHN DTUA link
Please note that anonymization services are not provided by our unit; researchers should consult the Data Science Center (BDSC) for assistance with anonymization.nked in descending order of preference):
5. FAIR Data Management Support Services Requested for SNSF and EU Applications
Effective 1 April 2026
Starting 1 April 2026, the Data Stewardship Biomed Unit (DSBU) will provide FAIR data management services for research projects conducted within the Faculty of Biology and Medicine UNIL–CHUV.
These services ensure compliance with FAIR principles (Findable, Accessible, Interoperable, Reusable) and Open Research Data (ORD) requirements from funders such as the Swiss National Science Foundation (SNSF) and European programmes.
In brief, research groups contribute to tailored FAIR data support—including consulting hours, metadata curation, dataset structuring and deposition, and repository guidance—with costs eligible for reimbursement by the SNSF.
Fees
One hour of DSBU services is billed at CHF 75 per hour, subject to prior validation by the Principal Investigator (PI) responsible for the project.
Subscription to paid data stewardship services is expected for any project submitted to SNSF or to European funding schemes.
This expectation may be waived if a member of the research group fulfills the role of data scientist, provided that their data stewardship qualifications are assessed and validated by the DSBU at the time of the budget reque
These services are provided as part of the DSBU’s paid FAIR Data Services©DSBU; for full details, please refer to the Costs section of the website.
DSBU support includes
The DSBU supports FBM UNIL–CHUV researchers across the full research data lifecycle, from dataset preparation and documentation to FAIR data sharing, metadata curation, repository submission, visibility and long-term preservation.
Personalized Assistance for Datasets
The DSBU provides personalized support to help researchers prepare their datasets for FAIR data sharing. This includes guidance on dataset structure, naming conventions, documentation, metadata standards, open file formats, repository selection and long-term preservation requirements.
We also provide tutorials and short, hands-on training sessions to help researchers apply good data management practices directly to their own datasets.
Dataset Structuration and Documentation for FAIR Data Sharing
DSBU support includes guidance on preparing datasets for FAIR data sharing, including assistance with metadata standards and open file formats for data sharing.
DataSquid@DSBU for Automated Data Documentation
We help researchers produce complete README files describing the dataset context, data types, acquisition methods, instrumentation, software, protocols, file organization and any other information needed to understand and reuse the data.
This support can be facilitated through DataSquid@DSBU:
https://wp.unil.ch/dsbu/tools_readme/
DataSquid@DSBU is an advanced tool that automates experimental data documentation by integrating information from equipment databases, laboratory protocols and acquisition workflows, ensuring comprehensive, consistent and reproducible research documentation.
Structured Dataset and Metadata Standardization with BioMetaXtract@DSBU
The DSBU also supports the production of structured metadata using BioMetaXtract@DSBU, with modality-specific metadata mapping for FAIR data sharing:
https://wp.unil.ch/dsbu/biometaxtractdsbu-multimodal-instrument-metadata-extraction-for-fair-data-sharing/
BioMetaXtract@DSBU ingests heterogeneous imaging and FACS datasets and harmonizes metadata using modality-specific standards such as REMBI, BIDS and MIFlowCyt. It combines raw file parsing, sidecar enrichment and metadata inference to produce standardized, validated and deposit-ready outputs, including quality flags and provenance tracking.
Metadata Curation and Repository Support
The DSBU supports research teams and assists with metadata curation for the sharing of datasets in recognized repositories, including:
Generalist FAIR Repositories
- Zenodo – FBM UNIL–CHUV Community (link)
Institutional CHUV Repository
HORUS Dataset Catalog for sensitive, non-de-identifiable data (link)
Disciplinary FAIR Repositories
- ENA – European Nucleotide Archive
https://www.ebi.ac.uk/ena - EGA – European Genome-phenome Archive
https://ega-archive.org - BioImage Archive – EMBL-EBI BioImage Archive
https://www.ebi.ac.uk/bioimage-archive - EMPIAR – Electron Microscopy Public Image Archive
https://www.ebi.ac.uk/empiar - EMDB – Electron Microscopy Data Bank
https://www.ebi.ac.uk/emdb - MetaboLights – MetaboLights Metabolomics Repository
https://www.ebi.ac.uk/metabolights - EBRAINS – EBRAINS Research Infrastructure
https://www.ebrains.eu
This includes support for improving the quality, completeness and discoverability of dataset metadata, as well as guidance on repository requirements and submission workflows.
Data Reuse, Copyright and Licensing
The DSBU provides advice on data reuse, copyright and licensing, including the selection of appropriate licenses, access conditions and reuse statements for shared datasets.
We also support researchers in addressing ethical, legal and contractual aspects related to data sharing, including consent, restricted access, de-identification and data transfer or data use agreements when relevant.
Improving Dataset Visibility
The DSBU helps improve the visibility and impact of research datasets by supporting DOI/publication linkage, data citation, metadata quality, repository indexing and visibility through institutional platforms such as IRIS where applicable.
Long-Term Preservation
The DSBU supports secondary data deposition on institutional infrastructure, ensuring secure long-term preservation through tape-based archiving and alignment with institutional data retention requirements.
This support helps ensure that data related to publications, research outputs and institutional obligations remain preserved, traceable and accessible over the long term.
Tailored Workshops and Team-Based Data Support
To foster good data practices across the faculty, the DSBU also offers tailored workshops and team-based support, including:
- workshops on FAIR data, repository use, metadata standards and data documentation;
- live tutorials and demos on using DataSquid@DSBU and FAIRShare Explorer@DSBU;
- group support sessions by appointment for research teams, laboratories, platforms or departments.
Custom training sessions can be scheduled on demand and adapted to each team’s specific data types, workflows, tools and FAIR data sharing needs.
Personalized Assistance for Daatsets
- Tutorials and short, hands-on training sessions
- Guidance on preparing your dataset for FAIR data sharing.
- Assistance with metadata standards and Open file formats (link) for data sharing.
- Support to help produce a complete README file describing data types, acquisition methods, instrumentation, software, etc. using DataSquid → https://wp.unil.ch/dsbu/tools_readme/.
- DataSquid@DSBU is an advanced tool that automates data documentation for experiments by integrating with equipment databases and laboratory protocols, ensuring comprehensive, consistent, and reproducible research documentation.
- Support to help produce a structured Metadata using BioMetaXtract@DSBU for Metadata Mapping per Modality → https://wp.unil.ch/dsbu/biometaxtractdsbu-multimodal-instrument-metadata-extraction-for-fair-data-sharing/
- BioMetaXtract@DSBU ingests heterogeneous imaging and FACS datasets and harmonizes metadata using modality-specific standards like REMBI, BIDS and MIFlowCyt. It combines raw file parsing, sidecar enrichment, and inference to produce standardized, validated, and deposit-ready outputs, including quality flags and provenance tracking. link
- Metadata curation on the FBM/CHUV Zenodo Community and Horus Dataset Catalog
- Advice on data reuse, copyright, and licensing.
- Improve visibility of your Datasets
- Support with secondary data deposition on institutional infrastructure, ensuring secure long-term preservation through tape-based archiving.
Tailored Workshops and Team-Based Data Support
To foster good data practices across the faculty, the DSBU also offers:
- Workshops on FAIR data, repository use, metadata standards, and data documentation
- Live tutorials and demos on using DataSquid and FairShare Explorer
- Group support sessions (by appointment) for research teams, labs, or departments
Custom training sessions can be scheduled on demand and adapted to your team’s specific data types and needs.
Inclusion in Grant Applications
For projects generating experimental or clinical datasets supporting publications, DSBU data stewardship services are normally included included in SNSF and European grant applications.
An exception may be considered if a member of the research group fulfills the role of data scientist, provided that their data stewardship qualifications are assessed and validated by the DSBU at the time of the budget request.
These services are delivered through FAIR Data Services©DSBU which require a financial contribution from research groups and must therefore be included in the project budget at submission
SNSF Funding Available (up to CHF 10,000)
The FAIR Data Services©DSBU corresponds to eligible costs under the SNSF Open Research Data funding scheme.
Researchers are expected to include a request of CHF 8,000–10,000 per project , depending on the Data Stewardship service package selected, under the budget category:
Material costs – Costs for granting access to research data (Open Research Data).
Budget Request at Submission
As SNSF regulations do not allow additional funding requests after submission or grant award, researchers planning SNSF or EU proposals are encouraged to contact the DSBU early during proposal preparation.