BioMetaXtract can document datasets of several terabytes in just a few hours, making it a practical solution for large-scale, big-data repository deposits and FAIR sharing.
Developed by Stéphanie Battini, PhD Ph.D. in Medical Sciences from the University of Strasbourg
From native research files to standards-aligned, repository-ready metadata
BioMetaXtract©DSBU is a tool developed by Stéphanie Battini at the Data Stewardship Biomed Unit to help researchers extract, organize and standardize metadata directly from native research files.
Many scientific instruments automatically record rich technical information during data acquisition. This information is often stored inside the files themselves or in associated sidecar files, but it is not always easy to access, interpret or reuse. BioMetaXtract makes these internal metadata visible, structured and reusable.
The objective is to reduce the manual burden of dataset documentation and to support researchers in preparing their data for FAIR sharing, repository submission and long-term preservation.
BioMetaXtract extracts metadata from acquisition files, maps them to relevant community standards, and reorganizes them into repository-ready formats adapted to the data type and target repository.
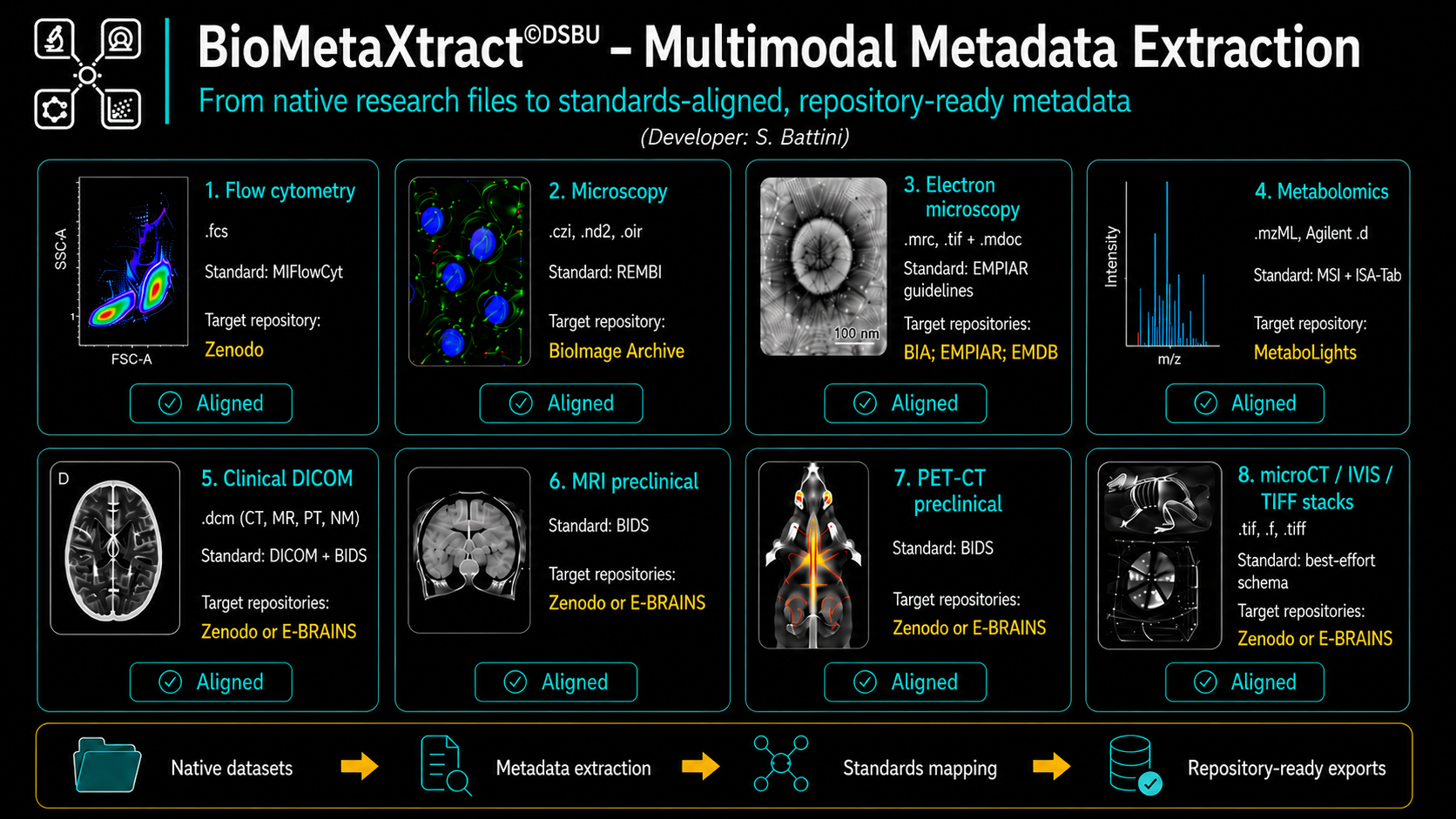
What BioMetaXtract does
BioMetaXtract supports the documentation workflow from raw data research files to FAIR metadata outputs.
It can
- read native metadata embedded in research files;
- automatically screen raw research files to detect key acquisition parameters produced by instruments or acquisition software;
- extract information from associated sidecar files when available. Sidecar files are additional files stored alongside the main raw data files, often generated by the instrument, acquisition software or analysis software, and containing complementary metadata such as acquisition settings, sample information, processing parameters or experimental annotations;
- generate structured JSON folders that can be reinjected into DataSquid©DSBU for internal data management and completion of the documentation;
- automatically reorganize the extracted metadata according to discipline-specific standards;
- generate extracted metadata under different metadata standards and in different file formats, depending on the targeted repositories recommended by the FBM;
- prepare structured metadata outputs that support deposition in recognized repositories;
- facilitate dataset documentation for FAIR data sharing and Open Research Data requirements;
BioMetaXtract supports the documentation workflow from raw research files to FAIR metadata outputs.
It can:
- read native metadata embedded in research files;
- automatically screen raw research files to detect key acquisition parameters produced by instruments or acquisition software;
- extract information from associated sidecar files when available. Sidecar files are additional files stored alongside the main raw data files, often generated by the instrument, acquisition software or analysis software, and containing complementary metadata such as acquisition settings, sample information, processing parameters or experimental annotations;
- automatically reorganize the extracted metadata according to discipline-specific standards;
- generate extracted metadata under different metadata standards and in different file formats, depending on the targeted repositories recommended by the FBM;
- prepare structured metadata outputs that support deposition in recognized repositories;
- facilitate dataset documentation for FAIR data sharing and Open Research Data requirements;
- generate structured JSON folders that can be reinjected into DataSquid for internal data management;
- support the ingestion of complementary information required by our LIMS.
DataSquid and BioMetaXtract are complementary tools. BioMetaXtract extracts and structures the technical metadata contained in raw research files, instrument outputs and associated sidecar files. DataSquid then complements this automatically extracted metadata origination from the FBM technological Platforms or contextual information entered by the research team, such as project information, dataset description, biological material, experimental protocols, storage location and data-sharing requirements.
Together, these two sources of information make it possible to produce a more complete and coherent dataset documentation. The metadata generated by BioMetaXtract can be enriched within DataSquid and then exported in practical formats, such as README files or Excel tables, which can be directly used for dataset documentation, internal data management, long-term storage preparation or FAIR data sharing.
In practice, BioMetaXtract helps researchers transform instrument-generated metadata into understandable, standardized and reusable information through an automated workflow. The extracted metadata are screened, structured and reorganized automatically, while remaining available for user review and completion when needed. Combined with the contextual metadata managed in DataSquid, these outputs provide a complete documentation layer that is easier to review, reuse and adapt to the requirements of targeted repositories.
Why this matters
Research datasets are often difficult to reuse because important contextual information is missing, scattered or stored in technical formats that are hard to interpret.
For example, a microscopy file may contain information about the microscope, objective, detector, laser wavelengths, channels and acquisition settings. A flow cytometry file may contain parameters related to the cytometer configuration and measured channels. A DICOM (Digital Imaging and Communications in Medicine, the universal clinical imaging format) file may contain information about imaging modality, acquisition date, scanner settings and image structure.
BioMetaXtract helps capture this information automatically, so that datasets can be better described, checked, shared and preserved.
This supports:
- improved dataset documentation;
- better traceability of data acquisition;
- easier preparation of repository submissions;
- alignment with FAIR principles;
- reduced manual metadata entry;
- better long-term reuse of research data.
Supported data modalities and standards
BioMetaXtract is designed as a multimodal metadata extraction tool. It supports several types of research data commonly produced within biomedical and life science research environments.
Flow cytometry
For flow cytometry data, BioMetaXtract extracts metadata from .fcs files (FCS, Flow Cytometry Standard) and aligns them with the MIFlowCyt (Minimum Information about a Flow Cytometry Experiment) standard.
The extracted metadata can support documentation and deposition workflows, for example in Zenodo or other appropriate repositories depending on the sharing strategy.
Current support includes extraction of key metadata from:
- FCS files (
.fcs) - FlowJo (
.wsp) workspace sidecar files (gating hierarchy, compensation, analysis groups)
Microscopy
For light microscopy data, BioMetaXtract supports formats such as:
- Zeiss (
.czi) - Zeiss LSM (
.lsm) - Leica (
.lif) - Nikon (
.nd2) - Olympus (
.oir,.vsi) - Generic TIFF / OME-TIFF (
.tif,.tiff,.ome.tif,.ome.tiff) - Imaris (
.ims) - Neurolucida (
.dat)
Current support also includes companion sidecar files such as AxioVision XML metadata, MS Access acquisition databases, Leica .lifext pyramid companions, and Olympus .omp2info tile-mosaic manifests.
The extracted metadata are mapped to the REMBI (Recommended Metadata for Biological Images) international standard used by the European repository BIA(BioImage Archive).
BioMetaXtract extracts and structures metadata related to image acquisition, including instrument information and, when available, detailed acquisition parameters such as:
- microscope information;
- objective information;
- detector information;
- laser wavelengths;
- filter information;
- channel-level metadata;
- pinhole size;
- detector gain and offset.
These metadata are useful for preparing submissions to the BioImage Archive or others FAIR repositories and for improving the documentation of bioimaging big datasets.
Current support includes extraction of key metadata from images files and of metadata sidecar files as well as processing or analysis Imaris or Fiji files.
Electron microscopy
For electron microscopy data, BioMetaXtract supports formats such as:
- MRC (
.mrc) — the legacy Medical Research Council volume format used for cryo-EM - TIFF image stacks (
.tif) - SerialEM
.mdocacquisition metadata sidecar files
The extracted metadata are aligned with EMPIAR (Electron Microscopy Public Image Archive) repository guidelines.
Target repositories may include: BioImage Archive; EMPIAR; EMDB (Electron Microscopy Data Bank) depending on the nature of the dataset and the scientific domain.
This supports documentation workflows for electron microscopy datasets, including tomograms, snapshots, montage data and associated acquisition metadata.
Metabolomics
For metabolomics data, BioMetaXtract supports formats such as:
- mzML (
.mzml) - mzXML (
.mzxml) - NetCDF (
.cdf, Network Common Data Form) - Thermo RAW (
.raw) - Agilent
.dacquisition folders
The metadata are aligned with MSI (Metabolomics Standards Initiative) reporting recommendations and ISA-Tab (Investigation/Study/Assay) structures.
The tool supports metadata preparation for repositories such as MetaboLights, and can also support FAIR documentation workflows for datasets deposited in Zenodo, depending on the publication and sharing requirements.
Clinical DICOM imaging
For clinical imaging data, BioMetaXtract supports DICOM files such as:
- CT (Computed Tomography)
- MRI (Magnetic Resonance Imaging)
- PET (Positron Emission Tomography)
- NM (Nuclear Medicine)
- covering file extensions
.dcm,.dicom, and.ima.
The extracted metadata are based on native DICOM (Digital Imaging and Communications in Medicine) information.
For clinical datasets, BioMetaXtract will apply additional dedicated filters to identify and document key sensitive-data requirements, including:
- de-identification;
- consent;
- access restrictions;
- sensitive metadata pathways;
- institutional and legal requirements.
Depending on the research context and the sensitivity of the data, outputs may support deposition or metadata sharing through different repositories or catalogues.
For neuroscience-related imaging datasets, E-BRAINS may be an appropriate target repository. For other disciplines, Zenodo may be more appropriate, depending on the dataset type, sensitivity and publication requirements.
MRI, PET-CT and BIDS-compatible datasets structuration
For MRI and PET-CT data, including preclinical imaging workflows (Bruker ParaVision MRI and PET-CT studies), BioMetaXtract supports metadata extraction from imaging files and aims to organize them according to BIDS-compatible (BIDS = Brain Imaging Data Structure) documentation structures.
Current BIDS-related outputs should be considered as structured support for documentation and future repository preparation. Full BIDS compliance may require additional curation depending on the dataset and repository requirements.
microCT, IVIS and TIFF stacks
BioMetaXtract can also support metadata extraction from modalities such as:
- microCT (micro-computed tomography — e.g. SkyScan/Bruker reconstructions: TIFF stacks with acquisition logs)
- IVIS (In Vivo Imaging System — bioluminescence/fluorescence exports by PerkinElmer/Revvity, TIFF images with ClickInfo sidecars)
- TIFF image stacks
- derived imaging outputs (e.g. NRRD segmentation masks, Nearly Raw Raster Data,
.seg.nrrd)
For these modalities, no single mature community minimum-information standard may be available. BioMetaXtract therefore applies a best-effort structured metadata approach, capturing available native metadata and organizing them according to FAIR documentation principles.
For neuroscience-related imaging datasets, E-BRAINS may be an appropriate target repository. For other disciplines, Zenodo may be more appropriate, depending on the dataset type and publication requirements.
From extracted metadata to repository-ready outputs
BioMetaXtract is not only a metadata extraction tool. Its goal is also to help researchers move toward repository-ready documentation.
The workflow can be summarized as follows:
- Native datasets
Researchers provide native acquisition files generated by instruments or acquisition software. - Metadata extraction
BioMetaXtract reads embedded metadata and available sidecar files. - Standards mapping
The extracted metadata are reorganized according to relevant community standards, such as MIFlowCyt, REMBI, EMPIAR guidelines, MSI / ISA-Tab, DICOM or BIDS-inspired structures. - Repository-ready exports
The output can support dataset documentation and preparation for deposition in appropriate FAIR repositories.
What researchers gain
BioMetaXtract helps researchers save time and improve the quality of dataset documentation.
It supports:
- automatic extraction of technical metadata;
- more complete dataset descriptions;
- better alignment with FAIR principles;
- easier preparation for repository submission;
- improved reproducibility and reuse;
- better traceability from acquisition files to published datasets.
By extracting and structuring metadata early, BioMetaXtract helps ensure that important acquisition information is not lost when data are prepared for sharing or long-term preservation.
BioMetaXtract is therefore part of an evolving DSBU ecosystem designed to support researchers throughout the FAIR data lifecycle: from acquisition metadata to dataset documentation, repository submission and long-term preservation.