
Pourquoi passer à une IA locale ?
Par décision de la Direction, les données sensibles au sens de la législation suisse ne doivent pas être traitées dans des solutions cloud. Le recours à un modèle local constitue l’alternative recommandée.
Les LLM commerciaux (ChatGPT, Claude, Google Gemini…) envoient requêtes et fichiers vers des centres de données externes. Avec LM Studio + Gemma 3n E4B, tout se déroule sur votre ordinateur :
- 100 % open‑source : Le code, les poids et les outils sont librement accessibles, modifiables et auditables, garantissant une transparence totale et une maîtrise complète de vos données.
- Aucune donnée transmise à des serveurs distants : vos informations restent chez vous (le modèle fonctionne entièrement hors ligne).
- Indispensable pour les données sensibles au sens de la législation suisse (données de santé, opinions politiques ou religieuses, données relatives à des procédures pénales, etc.). Également utilisable pour les documents privés ou liés au secret de fonction, en complément de Microsoft Copilot Chat institutionnel.
- Performances désormais crédibles face aux solutions commerciales : Gemma 3n E4B atteint presque un score de 1300 sur Arena quand les derniers modèles cloud sont à ~1500.
- Consommation maîtrisée : sur un MacBook Air M2 (~20 W), le processus d’inférence (requête + réponse) utilise bien moins d’énergie qu’un serveur avec GPU Nvidia H100 (~700 W), souvent employé pour les modèles commerciaux.
Installer LM Studio
- Téléchargez l’application gratuite sur https://lmstudio.ai.
- Lancez l’installateur, puis ouvrez LM Studio. Aucun compte n’est requis.
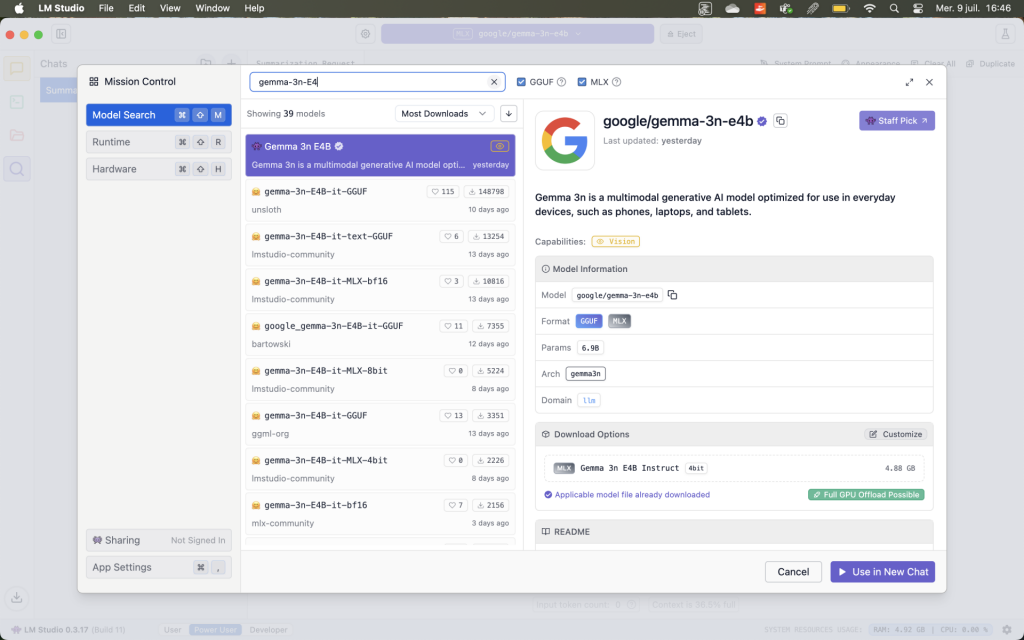
Ajouter le modèle gemma-3n-E4B
- Dans la barre de recherche de LM Studio (Discover), tapez gemma-3n-E4B.
- Sélectionnez la version GGUF (environ 4 Go) plutôt que la version MLX (environ 11 Go, trop lourde pour 16 Go de RAM).
- Cliquez sur Download pour copier le modèle (quelques Go) sur votre machine.
- Une fois le téléchargement terminé, cliquez sur Load pour le charger.
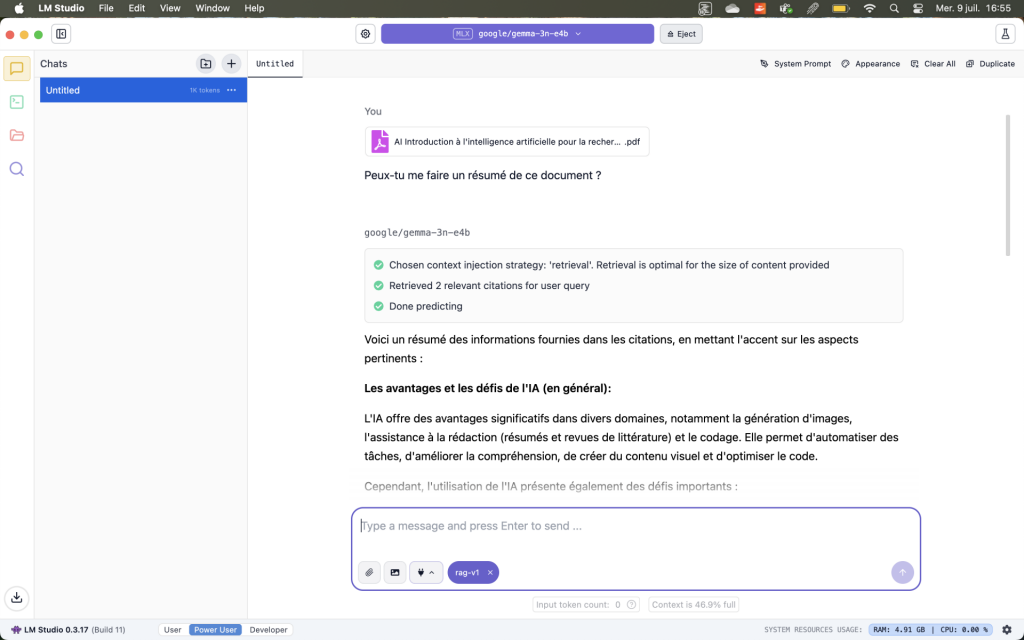
Travailler en toute confidentialité
Glissez-déposez vos PDF, DOCX ou rapports internes dans la fenêtre de chat (nécessite d’attendre que le document soit chargé). LM Studio indexe et interroge vos documents sans qu’ils sortent de votre ordinateur. Pour les données sensibles, c’est actuellement la seule approche conforme aux exigences de l’UNIL, car aucune donnée ne quitte votre poste de travail.
Pourquoi le modèle local Gemma 3n E4B ?
- Troisième génération « nano » (3n) : pensée pour tourner sur des PC grand public sans matériel spécialisé.
- E4B : Effective 4 Billion — environ 4 milliards de paramètres, un petit modèle pensé pour smartphones et PC.
- Format GGUF : fichier unique prêt à l’emploi, déjà quantisé, reconnu par tous les grands front-ends (LM Studio, Ollama, GPT4All, etc.).
- Equilibre poids/performance optimal : environ 4 milliards de paramètres (E4B) suffisent pour obtenir un score autour de 1300 sur Arena (https://arena.ai/leaderboard) – contre ~1500 pour les tout derniers modèles cloud.
- Optimisé Apple Silicon : fonctionne efficacement sur les puces M1 à M5.
- Détails officiels : https://deepmind.google/models/gemma/gemma-3n/
Alternatives possibles
Parmi les alternatives possibles figurent Ollama et GPT4All. Pour ceux qui débutent avec l’IA locale, LM Studio demeure l’option la plus accessible. D’autres modèles open source peuvent aussi être trouvés sur Hugging Face. Sur machines disposant de 32 Go de RAM ou plus, gpt-oss-20b (OpenAI) est envisageable. À 16 Go, gemma-3n-E4B reste le meilleur choix : même gemma-3-12b-it (le concurrent le plus proche avec un score Arena ~1330) ne parvient pas à se charger en conditions normales d’utilisation.
Le Centre informatique peut également mettre à disposition des modèles locaux sur ses propres infrastructures, offrant une alternative aux installations sur poste personnel.