
Table des matières
Analyse digitale et interprétations
Objectif
Notre étude du corpus se déroule en deux parties. Premièrement, nous comparons l’évolution de certains champs lexicaux dans les deux journaux, et nous identifions des groupes de mots liés par articles communs dans le corpus. Ce travail est effectué à l’aide d’IRaMuTeq, un logiciel d’analyse de texte. D’autre part, nous effectuons une analyse de sentiments simple et non-supervisée.
Préparation des données
Figure 2: Schéma de données associées à un article dans la base de données Le Temps
Afin d’utiliser IRaMuTeQ, nous avons transformé les données acquises de l’archive Le Temps en corpus lisible par le logiciel avec un script Python, puis agrégé tous les articles ensemble. Nous écartons aussi les articles avec plus de 75% de caractères spéciaux4. Après une analyse d’un échantillon, il nous a paru judicieux de les éliminer de notre corpus (soit une dizaine d’articles par mois).
Analyse textuelle avec IRaMuTeQ
Classification et similitudes
A l’aide d’IRaMuTeQ, nous appliquons la méthode Reinert de classification hiérarchique descendante. Celle-ci fonctionne de la manière suivante :
- Segmenter le texte.
- Observer la distribution par segment de chaque forme après lemmatisation.
- Classer les segments de texte dans des catégories différentes en fonction des mots qu’ils contiennent.
Une fois les classes identifiées, nous pouvons étudier la spécificité de certains mots au fil du temps et ainsi observer comment évolue le vocabulaire des deux journaux.
Sur notre corpus, effectuons une classification à trois niveaux. La première, en 8 classes, concerne l’ensemble du corpus (voir figure 3) et permet d’effectuer un premier tri des segments de texte.
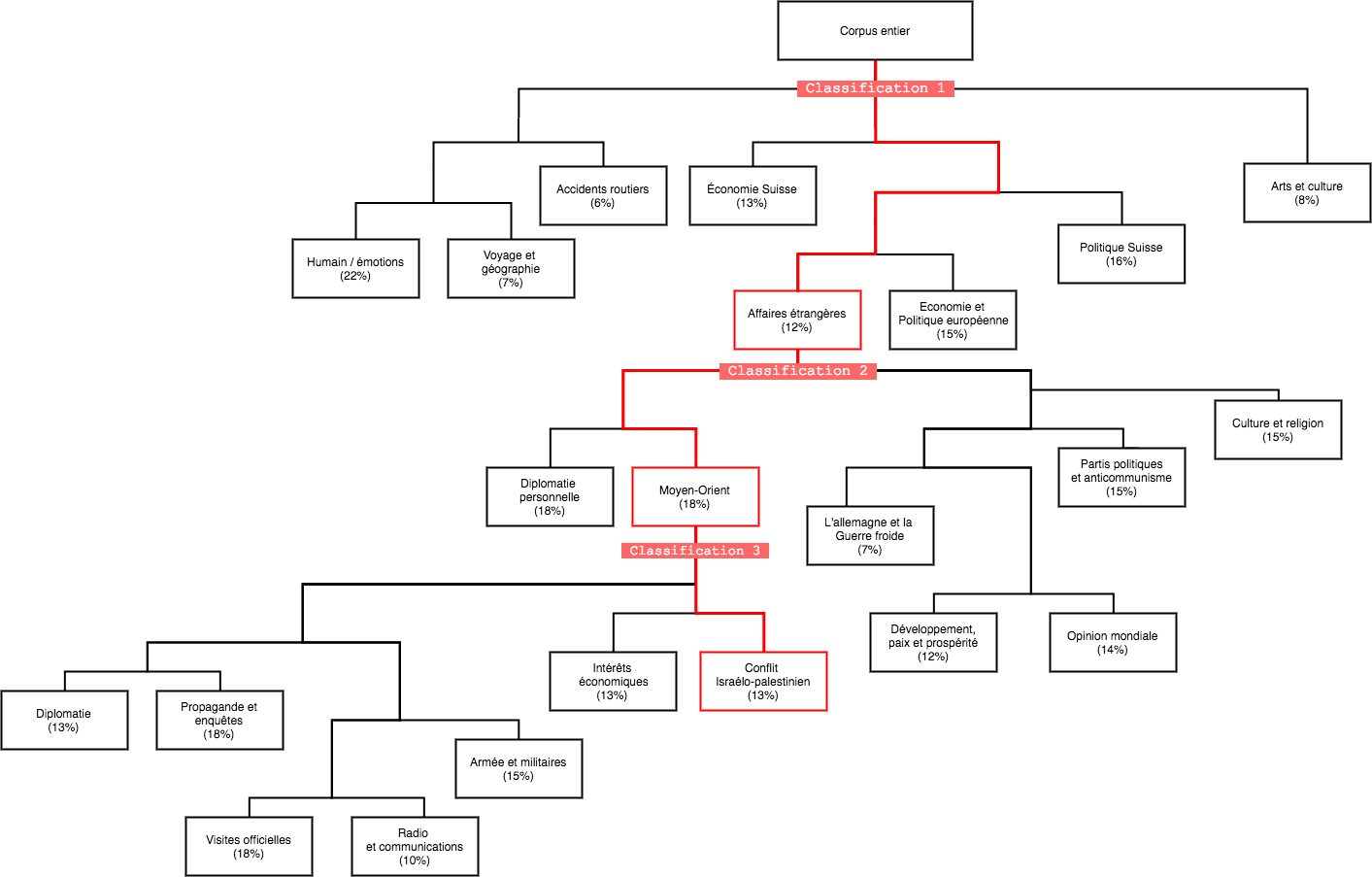
Figure 3: schématisation de la classification, en rouge les classes explorées
Nous restreignons ensuite notre corpus aux segments de texte de la classe « affaires étrangères » et effectuons une nouvelle classification (à 7 classes) pour raffiner notre analyse. Enfin, en choisissant la classe « Moyen-Orient », nous observons que celle-ci concerne aussi des textes relatifs à des évènements dont la pertinence au conflit israélo-palestinien est discutable (ex : sur l’Arabie Saoudite). Nous effectuons une dernière classification (7 classes) pour identifier les segments de textes ne concernant que les relations israélo–palestiniennes (environ 3775 segments).
Nous dressons aussi ci-dessous le graphe des occurrences des mots de cette classe.5 En utilisant Gephi et l’algorithme Fruchterman-Reingold, nous obtenons la figure ci-dessous. La taille d’un mot est proportionnelle à sa fréquence d’occurrence, un lien est tracé entre deux mots s’ils se retrouvent dans le même segment de texte. L’épaisseur est proportionnelle au nombre de segments partagés.

Figure 4: Graphe de cooccurrences de la classe « Israël-Palestine »
L’analyse de similitudes permet de visualiser les liens entre les formes d’une même classe. Elle donne un aperçu global de la vision des segments concernant les relations israélo-palestiniennes. Le graphe permet aussi de visualiser la pertinence de la classification.
Sur toute la période, le mot « Israélien » est le plus présent dans le sous-corpus et a un rôle central car il est relié à la plupart des formes observées. Evidemment, le champ lexical de la guerre est fortement représenté, dû aux dates que nous avons sélectionnées et qui sont des périodes de conflits. Outre ce champ lexical, on observe aussi un lien fort entre le mot « Israélien » et les mots tels que « territoire », « arabe », « gouvernement », « occuper », « frontière », « général » et « secrétaire » (pour « secrétaire général »). On comprend donc qu’il s’agit là de la légitimité de l’état israélien, de l’état de ses frontières ainsi que de ses relations avec le monde arabe. On peut donc déjà observer que de manière générale, les journaux auront une vision du conflit davantage centrée sur les Juifs et l’état israélien que sur la Palestine ou le monde arabe. On notera par ailleurs l’absence du mot « Palestine » ou du champ lexical de la décolonisation.
Spécificités
Pour compléter notre analyse sur Iramuteq, nous étudions aussi la spécificité de certains mots au fil du temps (la spécificité d’un mot est un indicateur de sa pertinence à une variable, ici l’année de publication) ; les valeurs transformées à l’intervalle [-1, 1] sont données par la couleur plus ou moins foncée selon qu’une forme est plus ou moins spécifique à une année. Nous avons choisi des mots qui nous paraissent pertinents pour évaluer l’opinion exprimée par les journaux.
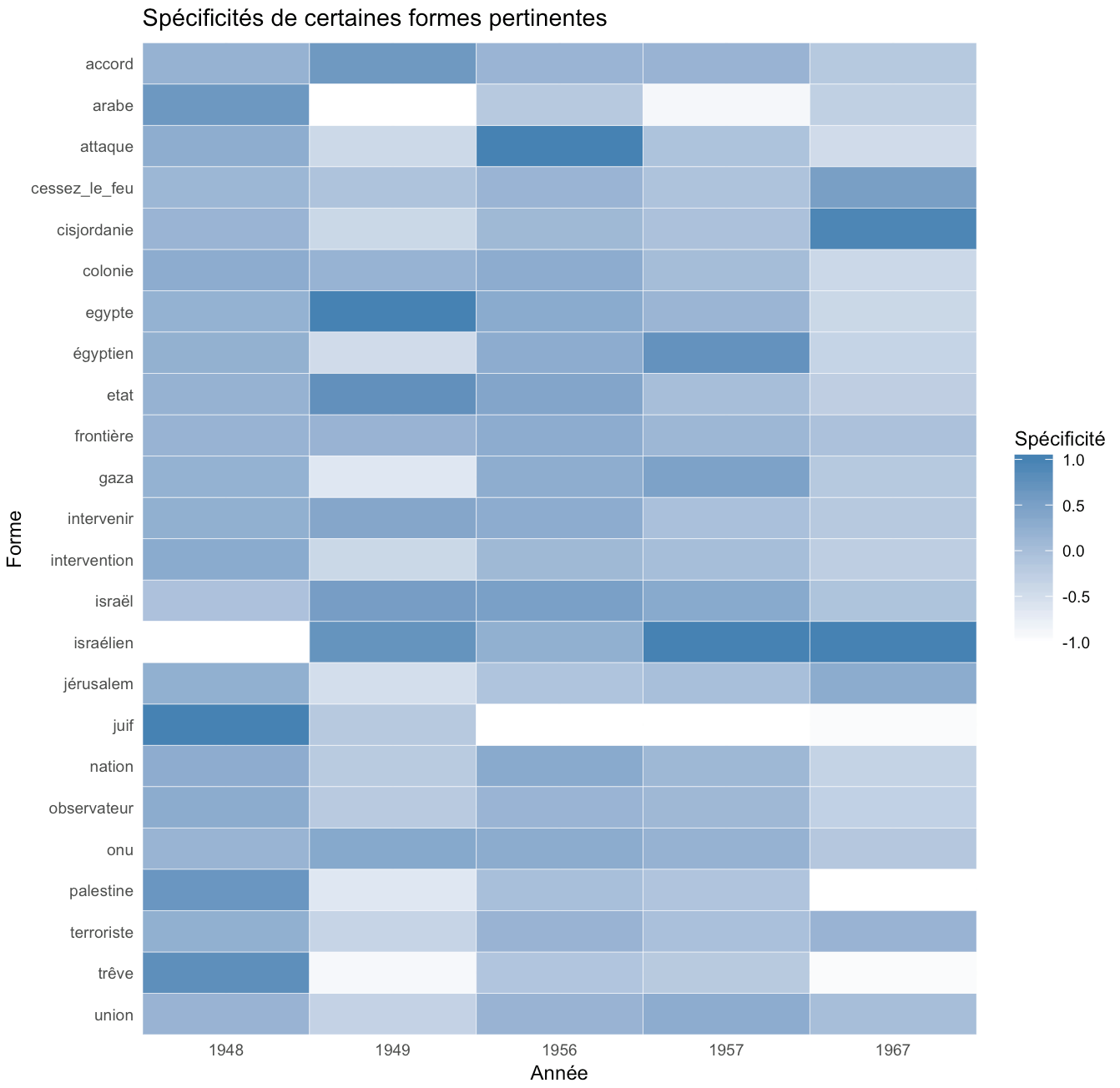
Le mot « colonie », par exemple, voit sa spécificité diminuer progressivement entre 1948 et 1967, indiquant que le thème colonial était plutôt d’actualité en 1948 et qu’il est devenu de moins en moins traité au fil du temps. Cependant, cette analyse est biaisée par le contexte historique d’après-guerre, où la question des colonies n’est pas spécifique aux Israéliens mais concerne toute l’Europe.
Il est donc intéressant de considérer plusieurs mots en même temps, comme par exemple « juif » et « israélien ». La première forme est très présente en 1948 et diminue en 1949 avant de disparaitre en 1956. La deuxième forme quant à elle apparait en 1949 et augmente fortement jusqu’en 1956-1957. On peut donc penser à une substitution dans le vocabulaire du mot « juif » par le mot « israélien ». De plus, nous observons une diminution de la pertinence du mot « Palestine » dans les journaux. La perception du conflit se concentre sur la vision d’Israël et moins sur celle de la Palestine. Le changement de spécificité pour les formes « juif » et « israélien » peut aussi s’expliquer par une évolution du langage dans le monde occidental, qui reflète quand même un changement de mentalité et d’opinion quant à la légitimité de l’état d’Israël.
D’autres formes en relation avec le conflit ont aussi été ajoutées. Ainsi on observe que « Israël » reste stable au cours du temps, ce qui renforce l’idée que le changement de « juif » vers « israélien » n’est pas qu’une évolution linguistique. Le mot « frontière » conserve une spécificité relativement stable, suggérant que le sujet ne quitte pas l’actualité. La spécificité de la forme « arabe » est haute dans les années où le conflit est actif, mais perd rapidement sa pertinence après.
Ces différents éléments laissent penser que le traitement du conflit israélo-palestinien commence en 1948 avec des positions moins marquées que les années qui suivent, qui se rapprochent progressivement du point de vue israélien.
Machine Learning
Pour répondre à la question de l’évolution des lignes éditoriales des journaux, essayons un algorithme d’analyse de sentiment pour estimer la positivité et négativité de certains mots relatifs au conflit, en particulier les mots « Israël » et « Palestine ». Par manque de données labélisées en français, nous n’avons finalement pas pu utiliser de méthode supervisée. Nous avons donc implémenté un modèle basé sur des méthodes non-supervisées, qui est présenté dans le papier de Lin et He.
Le modèle est le suivant :
- Nous supposons que chaque mot dans chaque texte exprime un sentiment positif avec une certaine probabilité. À partir de ces probabilités, nous déduisons la probabilité qu’un article ait une connotation positive et celle qu’un mot exprime un sentiment positif en général dans le corpus.
- Nous estimons ces probabilités utilisant un algorithme de type Markov Chain Monte Carlo. Pour ce faire, nous supposons que certains mots sont toujours positifs ou négatifs : bon, bien, agréable, … expriment toujours un sentiment positif, et mal, mauvais, malheureux, … toujours un sentiment négatif.
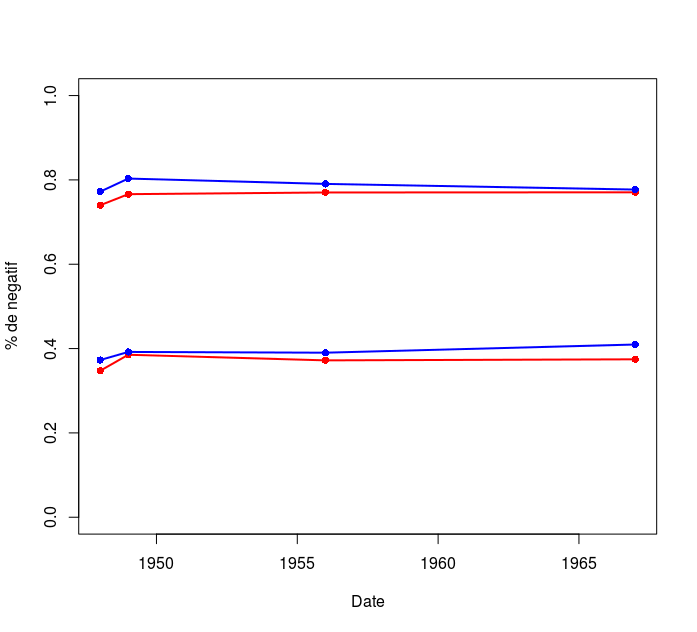
Figure 5: En haut, les courbes relatives au mot « Palestine » et en bas les courbes relatives au mot “Israël”, les courbes bleues sont celles de la Gazette de Lausanne et en rouge du Journal de Genève.
Selon notre modèle, le mot « Israël » est utilisé à 38.4% de manière négative, contre 76.6% pour le mot « Palestine ». Dans les 950 articles où ces deux mots apparaissent ensemble, le premier est négatif à 39.2% du temps et 76.5% pour le second.
Les résultats de notre modèle confirment ce que l’analyse précédente suggéraient : « Palestine » correspond à un sentiment plus négatif que « Israël », et il semblerait que (au moins pour la GDL) cette divergence s’accentue. De manière générale, le JDG semblerait plus neutre, attitude à laquelle on s’attendrait de la part d’un journal plus porté sur les relations internationales.