
Accueil | Contexte historique et problématique du travail | Méthodologie | Interprétation des résultats | Bibliographie | Annexes
Constitution des sous-corpus d’intérêt
Notre premier objectif est d’extraire du corpus initial, constitué des archives de la GDL et du JDG entre 1945 et 1995, les articles pertinents pour notre analyse. Pour ce faire, nous classons les articles en sous-corpus d’intérêt ayant trait à la décolonisation.
Notre premier sous-corpus contient tous les articles mentionnant le terme « décolonisation » (sous-corpus 1). Ce sous-corpus est thématique et a pour vocation de rassembler tous les articles publiés dans la GDL et le JDG portant très vraisemblablement sur la décolonisation.
Nous avons ensuite créé un second sous-corpus composé d’articles mentionnant à la fois le terme « décolonisation » et le mot « Suisse » afin d’observer d’éventuelles catégories de discours liant la Suisse et la décolonisation (sous-corpus 2). Ce sous-corpus devrait pouvoir également mettre en évidence les pays décolonisés plus fortement liés au terme « Suisse » dans la presse libérale romande.
Les extractions des sous-corpus ont été effectuées avec les scripts Python[1].
Nous avons également constitué une liste des nouvelles indépendances en Afrique et Asie entre 1945 et 1995. Pour chaque nouvelle indépendance, nous avons ainsi noté l’année de celle-ci, l’ancien nom du territoire, le nom de l’empire colonial qui le contrôlait, ainsi que le nom de l’état nouvellement proclamé. Ces informations servent lors de la formation de nos sous-corpus et N-grams, mais peuvent aussi être des facteurs explicatifs permettant d’interpréter d’éventuelles différences de discours entre les différentes décolonisations.
Traitement des données
En premier lieu, nous avons généré pour chaque pays décolonisé un n-gram (en utilisant le nom du pays pour la recherche) sur lequel nous avons rapporté la date de son indépendance. Pour les pays d’intérêt dont le nom a changé lors de leur indépendance, nous avons pris en compte l’ancien et le nouveau nom. Ces 56 n-grams nous permettent de faire une première observation quant à l’intérêt suscité par l’accession à l’indépendance des différents pays dans la GDL et le JDG.
Fig. 1 : Sélection de quelques n-grams :
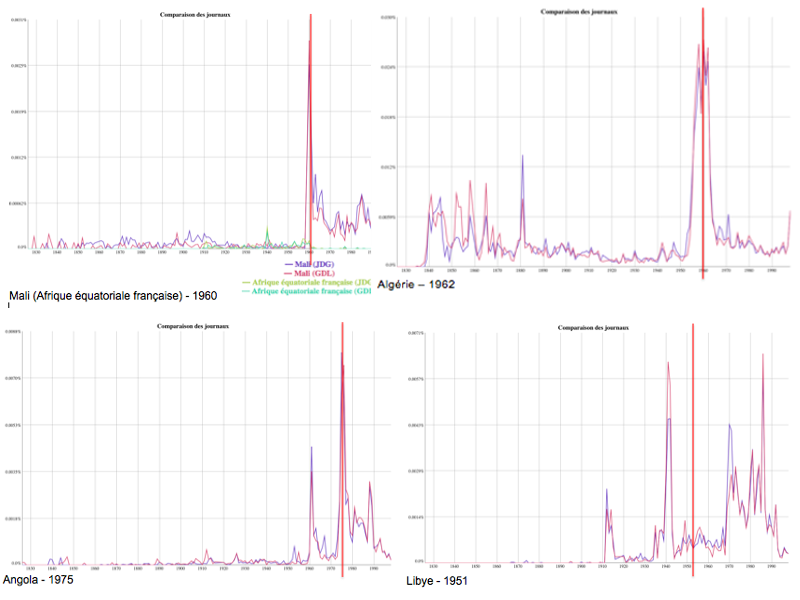
Dans un deuxième temps, nous avons plus spécifiquement analysé les données des archives de la GDL et du JDG. Ce traitement a comme objectif principal d’évaluer l’intérêt porté par les deux journaux aux articles rassemblés dans les sous-corpus en employant quelques métriques simples. Une première métrique consiste à évaluer la couverture de chaque pays en totalisant les mots de chaque article mentionnant un pays donné. Une seconde métrique considère le nombre moyen de mots par article pour chaque pays. L’utilité de cette métrique repose sur l’hypothèse que les articles plus longs indiquent un intérêt accru et comportent éventuellement une analyse de fond, alors que les articles courts ont tendance à être plus factuels. Nous mesurons aussi l’évolution de ces métriques pour chaque sous-corpus dans le temps, sans distinguer les pays, mais en indiquant à chaque année le nombre des nouvelles indépendances. Ces métriques peuvent également servir à diriger certains pointages qualitatifs.
A noter que nous employons des méthodes qui permettent à la fois d’interroger les données sur des 386points préétablis (p.ex répondant à la question : « A quelles dates et combien de fois est-ce que le Kenya est cité dans le corpus ? ») et d’utiliser les données pour faire ressortir des éléments inconnus des chercheurs (p.ex extraction de thématiques par l’analyse automatisée d’un sous-corpus).
Fig. 2 : Schéma résumant la méthodologie suivie :
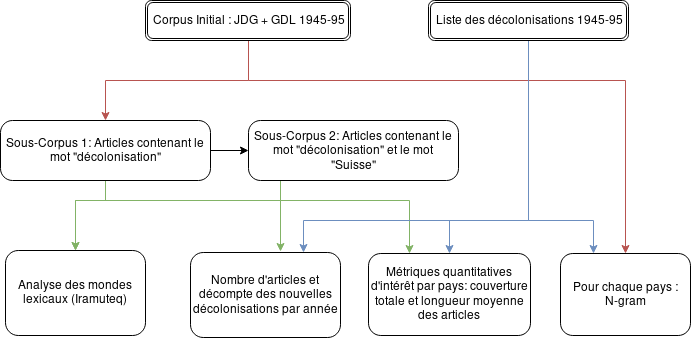
Visualisation de données
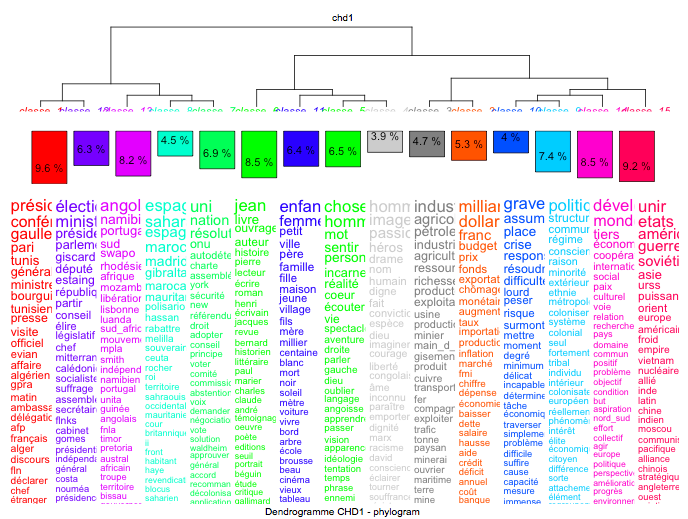
Nous utilisons la sortie par classe d’Iramuteq pour visualiser nos données et leur évolution dans le temps. L’intérêt mesuré quantitativement sera indiqué sous forme d’histogramme en fonction p.ex. des pays décolonisés, des dates de publication, etc. Par ailleurs, des diagrammes à barres (« bar plot ») nous permettent d’afficher les fréquences relatives entre p.ex. co-mention de pays d’intérêt et du terme « décolonisation ». Finalement, nous avons dessiné un schéma illustrant l’extraction de nos sous-corpus et le traitement effectué sur ceux-ci.
Fig. 3 : Visualisation des classes d’Iramuteq après le traitement de notre sous-corpus 1 (tous les articles parlant de décolonisation entre 1945 et 1995):
Problèmes et limites méthodologiques
Notre analyse porte sur un grand nombre d’articles que nous devons traiter de manière automatisée. Cette approche, bien que nécessaire, introduit plusieurs biais considérables. Ces biais sont notamment fortement conditionnés par le choix des mots-clés servant à la constitution des sous-corpus. Par exemple, l’inclusion du mot « guerre » dans l’objectif d’identifier des sous-corpus d’articles portant sur les nouvelles indépendances acquises par les armes mènerait à l’inclusion de nombreux articles ne traitant pas de guerres d’indépendance, mais de guerres internationales (faux positifs). De même, l’emploi de certaines périphrases ou l’omission du nom d’un pays (voire emploi d’un nom alternatif non considéré au préalable) dans un article donné provoque le rejet de celui-ci lors de la classification en sous-corpus (faux négatif). Dans notre approche, nous privilégions la minimisation des faux positifs. Une autre source de biais provient de la supposition qu’un article mentionnant un pays traite de celui-ci. Or, il est tout à fait possible qu’un pays mentionné ne joue qu’un rôle marginal dans l’article analysé automatiquement (faux positif). Finalement, l’imperfection de la numérisation des articles cause de faux négatifs (essentiellement).
L’utilisation des n-grams pour chacun des pays d’intérêt nous a également permis de mettre en lumière que certains noms de pays sont délicats à utiliser car ils peuvent faire référence à plusieurs objets. Le mot « Congo » par exemple peut-être utilisé pour le Congo Belge, la République du Congo ou encore la République Démocratique du Congo.
[1] https://github.com/cipri-tom/decolonisations