
Introduction · Corpus · Méthodologie · Résultats · Interprétation · Avantages et limites · Conclusion
Dans cette partie, nous exposons les visualisations que nous jugeons intéressantes pour notre analyse. Chaque visualisation est accompagnée des quelques mots expliquant l’intuition qui la sous-tend et comment nous l’avons obtenue.
Courbe de fréquence aux différentes échelles
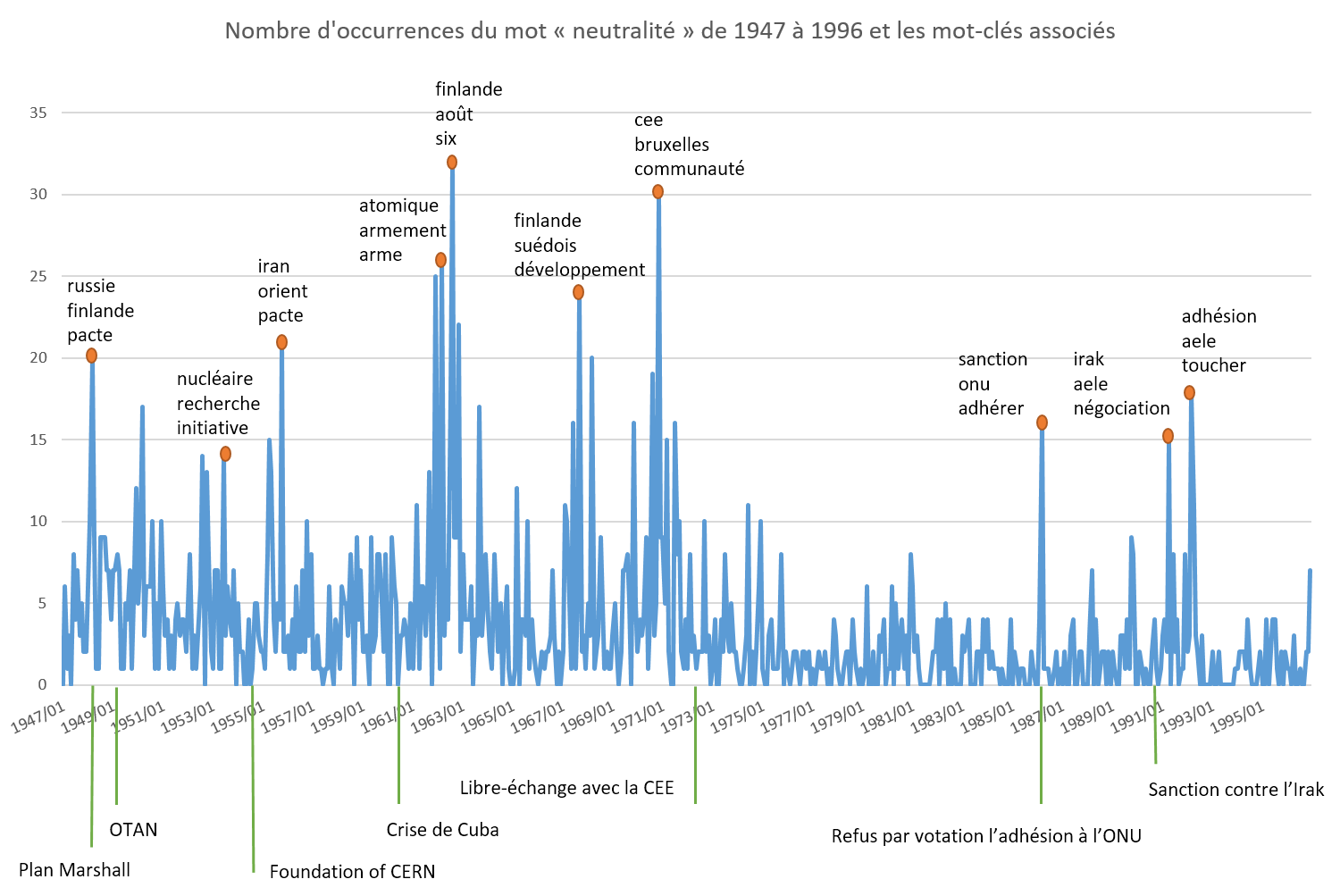
L’image ci-dessus illustre le changement de la fréquence du mot « neutralité » en Une (corpus «?neutralité / Une?»). Le comptage se fait sur tous les mois. Nous y ajoutons ensuite les mots représentatifs calculés via TF-IDF et quelques événements historiques pour mieux situer les pics sur la courbe dans le temps. Cette première figure met en lien les grands événements de la Guerre froide avec les articles associés. Nous pouvons faire le même exercice avec une échelle plus grande, celle de l’année, la courbe est similaire, mais les mots représentatifs s’avèrent plus difficiles à extraire.
Regroupement des segments de textes
Le regroupement des mots permet de retrouver les principaux thèmes évoqués en même temps que la neutralité. Le résultat ci-dessus est obtenu sur le corpus «?neutralité?». Nous distinguons bien deux groupes de mots liés à la relation internationale (en vert) et un groupe sur le gouvernement suisse (en rouge).

Après avoir regroupé les segments de textes, Iramuteq calcule automatiquement la distance ?2 entre chaque groupe de mot dans un sous-ensemble du corpus défini par une variable, par exemple une année précise. Ces valeurs représentent l’importance d’un groupe dans un sous-corpus donné. Autrement dit, elles représentent les thèmes les plus abordés sur un certain intervalle de temps. L’évolution de la distance de chaque groupe de mots se trouve sur la figure 3.

Graphe de similitude
L’objectif du graphe de similitude est très proche de celui du regroupement, c’est-à-dire de trouver les grands thèmes liés à la « neutralité ». Pour obtenir le résultat dans la figure 4, nous avons utilisé d’abord?ForceAtlas2, puis Noverlap pour former les groupes sans que les nœuds se superposent. Nous voyons d’abord que la « neutralité » reste bien proche de la « politique » et la « Suisse ». Puis?nous avons des groupes formés autour de «?l’indépendance?» et la «?défense?».

La méthodologie que nous présentons dans cette partie se limite à des méthodes classiques. Ce choix est non seulement dû aux moyens dont nous disposons, mais aussi à la qualité de nos données et à notre expertise dans le domaine.