Our service is knowledgeable about metadata standards and readme files for datasets. Metadata and readme files are absolutely necessary for a complete understanding of the research data content and to allow other researchers to find and re-use your data.
1. Metadata Definition
Metadata is commonly defined as “data about data”, meaning it provides descriptive or contextual information about a dataset.
Metadata is “data that describes, explains, locates, or otherwise makes it easier to retrieve, use, or manage an information resource.” In the context of research data management, metadata provides structured information about your datasets, including:
- Descriptive Metadata: Details that help identify and discover your data (e.g., title, authors, keywords, abstract).
- Structural Metadata: Information about how the data is organized and related (e.g., file formats, data models, relationships between tables or images).
- Administrative Metadata: Technical and preservation information needed for long-term management (e.g., version history, file checksums, access rights, licensing).
Metadata should be as complete as possible, using the standards and conventions of a discipline, and should be machine readable. Metadata should always accompany a dataset, no matter where it is stored.
Well-crafted metadata ensures that your data are:
- Findable: Search engines and repository catalogs can locate your datasets.
- Accessible: Users know how and under what conditions they can retrieve the data.
- Interoperable: Common vocabularies and formats enable integration with other datasets or tools.
- Reusable: Clear context and provenance allow others (or your future self) to understand and repurpose the data correctly.
FAIR principles (Findable, Accessible, Interoperable, and Reusable)
Research data and metadata are made available in a format that adheres to standards, making them both human and machine-readable, in line with principles of good data governance and management, following FAIR principles (Findable, Accessible, Interoperable, and Reusable). It’s important to note that FAIR does not necessarily imply open accessibility, and sharing can occur in restricted or contractual forms if needed. However, metadata should be made as openly available as possible.
FAIR data principles
One of the grand challenges of data-intensive science is to facilitate knowledge discovery by assisting humans and machines in their discovery of, access to, integration and analysis of, task-appropriate scientific data and their associated algorithms and workflows. Force11 describes FAIR – a set of guiding principles to make data Findable, Accessible, Interoperable, and Reusable. The term FAIR was launched at a Lorentz workshop in 2014, the resulting FAIR principles were published in 2016 (link).
To be Findable:
F1. (meta)data are assigned a globally unique and eternally persistent identifier.
F2. data are described with rich metadata.
F3. (meta)data are registered or indexed in a searchable resource.
F4. metadata specify the data identifier.
To be Accessible:
A1. (meta)data are retrievable by their identifier using a standardized communications protocol.
A1.1. the protocol is open, free, and universally implementable.
A1.2. the protocol allows for an authentication and authorization procedure, where necessary.
A2. metadata are accessible, even when the data are no longer available.
To be Interoperable:
I1. (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
I2. (meta)data use vocabularies that follow FAIR principles.
I3. (meta)data include qualified references to other (meta)data.
To be Re-usable:
R1. (meta)data have a plurality of accurate and relevant attributes.
R1.1. (meta)data are released with a clear and accessible data usage license.
R1.2. (meta)data are associated with their provenance.
R1.3. (meta)data meet domain-relevant community standards.
SNSF Explanation of the FAIR Data Principles (PDF) (link)
Wilkinson et al. (2016), The FAIR Guiding Principles for scientific data management and stewardship, Scientific Data 3, doi:10.1038/sdata.2016.18 (link)
Our service guides researchers on making their data FAIR compatible. This involves ensuring that metadata is comprehensive and standardized.
With the help of our FAIRShare Explorer ©DSBUand DataSquid©DSBU tools, metadata definitions drive every step—from in-lab capture to final repository submission—transforming metadata collection into an integral, automated component of your research lifecycle.
2. Metadata Standards
FAIRShare Explorer ©DSBU: your Powerful Tool for Determining Data Category & Discipline-Specific Metadata Standards
Your Guide for particular file formats and disciplines.
What you’ll find in the Explorer:
- Complete list of repositories with key informative details for efficient submission: data types and formats, submission process, metadata standards, sharing licenses, and more
- For every repository and data type, we provide:
- A detailed description of the community-endorsed metadata schema (e.g. MIAME, DICOM, CDISC)
- Direct links to the official standard documents or registries
- Concrete guidance on preparing your metadata fields step by step (naming conventions, required vs. optional fields, controlled vocabularies)
- Repository Usage Recommendations from the FBM Dean’s Office and DSBU
- Indication on the type of support provided by the DSBU
→ Detailed explanations about the tool : link
External Ressources for disciplinary Metadata
Find standards applicable to your data type
FAIRsharing and Digital Curation Center are two resources to identify disciplinary metadata standards.
DataCite Metadata schema
Useful standard for describing general research datasets when there is no data category or discipline specific standard.
Details
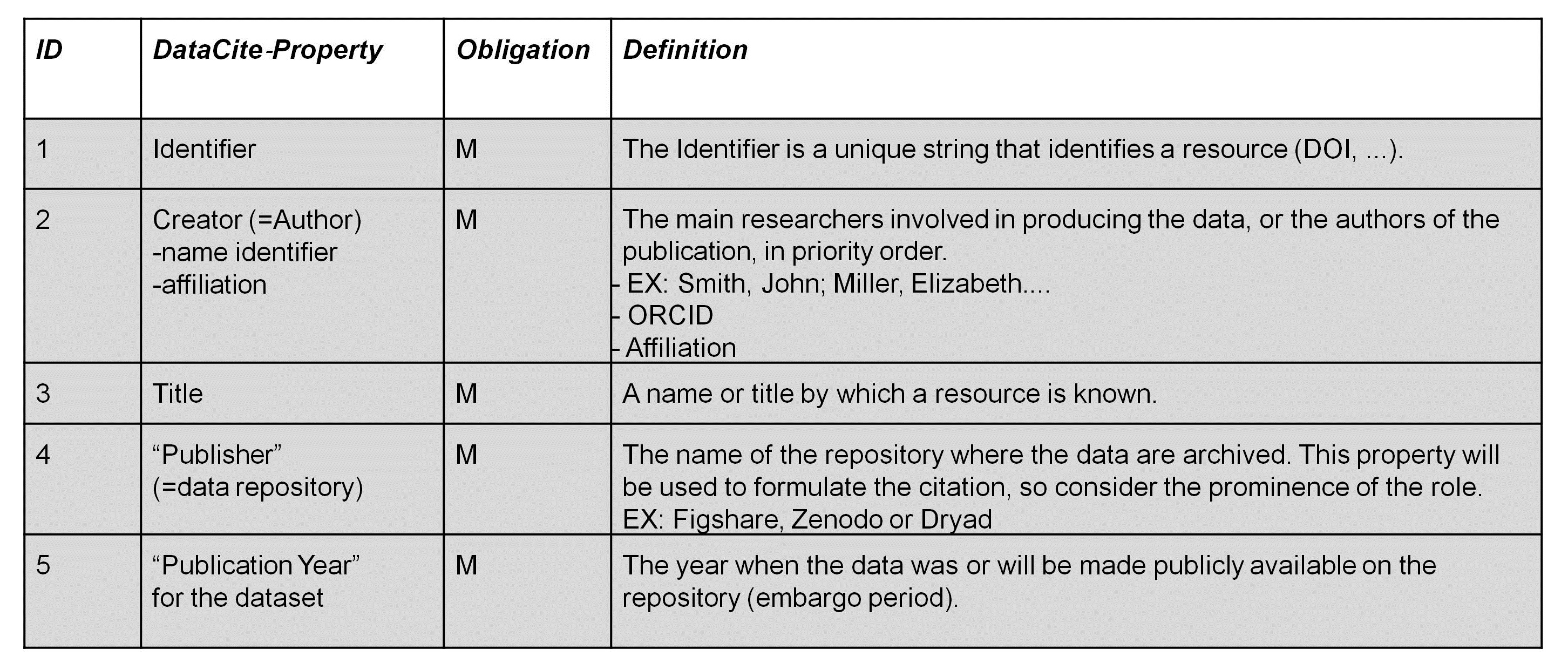
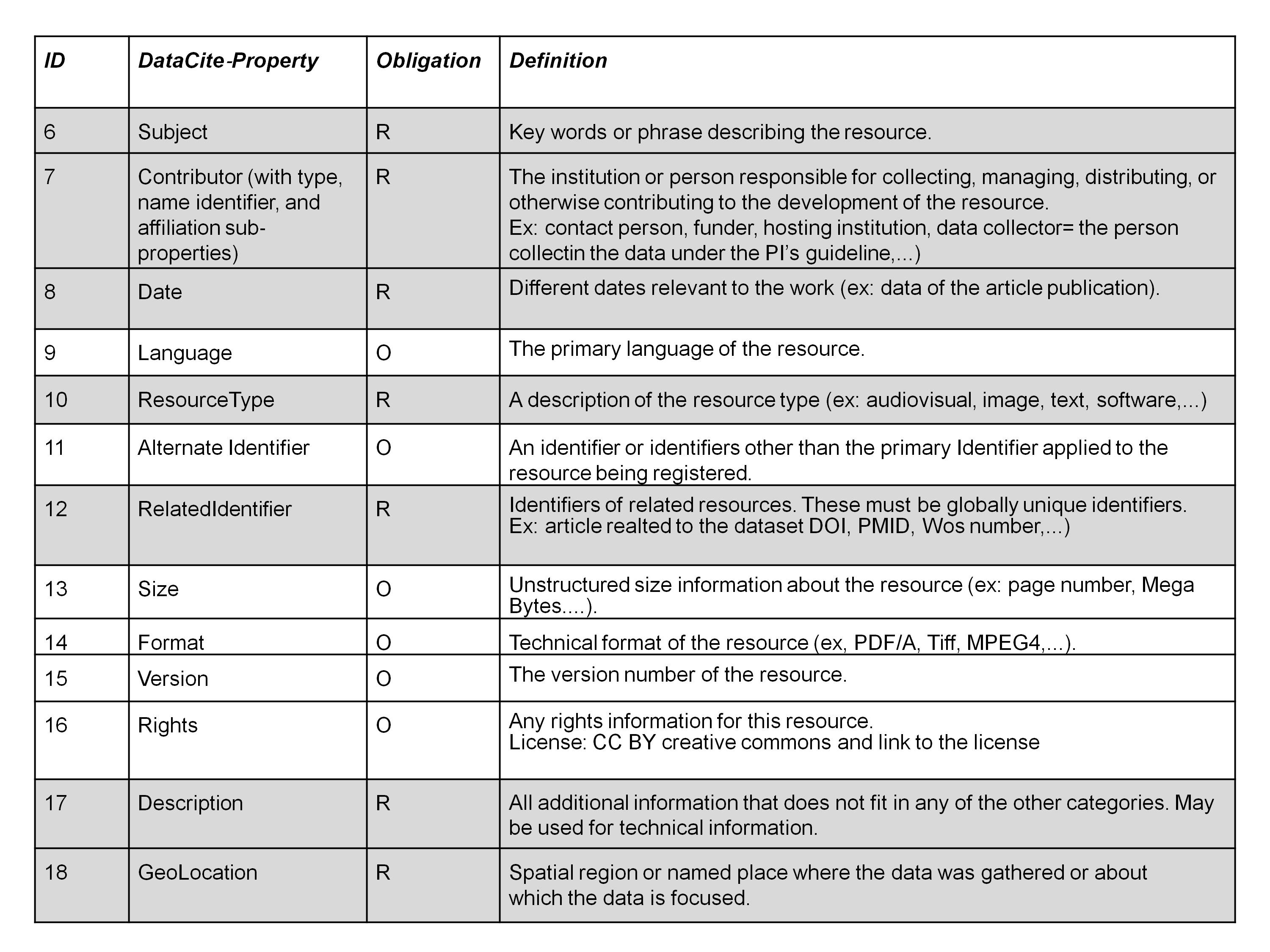
The DataCite Metadata Schema for Publication and Citation of Research Data distinguishes between 3 different levels of obligation for the metadata properties:
- Mandatory (M) properties must be provided,
- Recommended (R) properties are optional, but strongly recommended and
- Optional (O) properties are optional and provide richer description.
Table 1 and table 2 list the different items you should document about your dataset based on the 3 different levels of obligation.
Table 1: DataCite Mandatory Properties
{kind=link}

Table 2: DataCite Recommended and Optional Properties
{kind=link}

3. Readme file
A README file is a crucial component of dataset documentation, providing essential information to ensure that the data can be accurately interpreted and utilized by others, as well as by yourself in the future. It serves to enhance the usability, reproducibility, and transparency of your dataset.
Key Elements to Include in a README File
General Information:
- Dataset Title: Provide a clear and descriptive title for your dataset.
- Author Information: List the names, affiliations, and contact details of the principal investigator and any co-investigators.
- Date of Data Collection: Specify the dates when the data was collected.
- Geographical Location: If applicable, mention where the data was collected.
- Keywords: Include relevant keywords to describe the data’s subject matter.
Data and File Overview:
- File Descriptions: Provide a brief description of each file, including its format and purpose.
- File Structure: Explain the organization of the files and any relationships between them.
- File Naming Conventions: Describe the naming conventions used for files and directories.
Methodological Information:
- Data Collection Methods: Detail the procedures and instruments used to collect the data.
- Data Processing: Explain any processing or transformation applied to the data.
- Quality Assurance: Describe steps taken to ensure data quality and integrity.
Data-Specific Information:
- Variable Definitions: Define all variables, including units of measurement and possible codes.
- Missing Data: Specify how missing data is represented in the dataset.
- Data Formats: Indicate any specialized formats or abbreviations used.
Sharing and Access Information:
- Licenses or Restrictions: State any licenses or
restrictions associated with the data. - Related Publications: Provide references to publications that use or are related to the data.
- Citation Information: Offer a recommended citation for the dataset.
Best Practices:
- File Format: Write the README as a plain text file (e.g., README.txt) to ensure accessibility and longevity.
- Standardized Formatting: Use consistent formatting and terminology throughout the README.
- Clarity and Detail: Provide sufficient detail to allow others to understand and use the data without additional assistance.
DataSquid©DSBU : Automated Data Documentation
The tool seamlessly integrates with your local or institutional equipment databases and internal laboratory protocols to collect and organize all relevant sample details, acquisition parameters, processing workflows, and procedural information directly from instrument logs. By providing structured README files and Compliant metadata for each experiment, DataSquid ensures that every dataset is thoroughly documented—promoting consistency, transparency, reproducibility, and alignment with FAIR principles.
Metadata Management with DataSquid©DSBU
- Metadata Workbench with DataSquid As you collect and process your data, DataSquid captures metadata in real time—annotating files and populating the exact schema fields you will need later.
- Seamless Extraction & Submission When you’re ready to deposit, the tool auto-generates a fully formatted metadata package for your chosen repository. No manual re-entry required.
- Future API Automation We’re building direct API integrations so that once your metadata is validated, it can be pushed straight into repository submission forms—making your data truly publication-ready with a single click.
- By putting metadata front and center, this tool ensures your datasets are richly described, interoperable, and immediately reusable—transforming data sharing from an afterthought into an integrated, automated step of your research workflow.
For comprehensive dataset documentation, DataSquid©DSBU streamlines the creation of README files for efficient data management and sharing.
README File Generation Approaches:
- Retrospective Documentation: If experiments were conducted before being recorded in DataSquid, the tool generates a simplified README file to document past experiments effectively.
- Proactive Documentation: For new data acquisitions or analyses, README files are automatically created.
Key Features of DSBU Automated README Generation:
- README files are automatically generated for datasets stored on NAS-DCSR.
- A global README file is compiled for TAR documentation before archiving to tapes.
- README files are prepared automatically for data sharing on generalist repositories (e.g., Zenodo, Horus Dataset Catalog) during publication.
- Specialized metadata integration enables optimized sharing on domain-specific repositories (e.g., OMICS data).
→ Detailed explanations about the tool : Link